
# Golang 异常处理
在实际工程项目中,我们希望通过程序的错误信息快速定位问题,但是又不喜欢错误处理代码写的冗余而又啰嗦。Go语言没有提供像 Java、C#语言中的 try...catch 异常处理方式,而是通过函数返回值逐层往上抛。
这种设计,鼓励工程师在代码中显式的检查错误,而非忽略错误,好处就是避免漏掉本应处理的错误。但是带来一个弊端,让代码啰嗦。
# 一、Golang 错误处理
# 1. 错误 & 异常
错误指的是可能出现问题的地方出现了问题。比如打开一个文件时失败,这种情况在人们的意料之中 。
而异常指的是不应该出现问题的地方出现了问题。比如引用了空指针,这种情况在人们的意料之外。可见,错误是业务过程的一部分,而异常不是 。
Go 中的错误也是一种类型。错误用内置的 error 类型表示。就像其他类型的,如 int,float64。错误值可以存储在变量中,从函数中返回,等等。
# 2. 演示错误
我们来尝试打开一个不存在的文件:
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/test.txt")
if err != nil {
fmt.Println(err)
return
}
//根据f进行文件的读或写
fmt.Println(f.Name(), "opened successfully")
}
在 os 包中有打开文件的功能函数:
func Open(name string) (file *File, err error)
如果文件已经成功打开,那么 Open 函数将返回文件处理。如果在打开文件时出现错误,将返回一个非 nil 错误。
如果一个函数或方法返回一个错误,那么按照惯例,它必须是函数返回的最后一个值。因此,Open 函数返回的值是最后一个值。
处理错误的惯用方法是将返回的错误与nil进行比较。nil 值表示没有发生错误,而非 nil 值表示出现错误。在我们的例子中,我们检查错误是否为 nil。如果它不是 nil,我们只需打印错误并从主函数返回。
运行结果:
open /test.txt: No such file or directory
我们得到一个错误,说明该文件不存在。
# 3. 错误类型
Go 语言通过内置的错误接口提供了非常简单的错误处理机制。
在 Go 语言中,错误是一个带有以下定义的接口类型:
type error interface {
Error() string
}
它包含一个带有 Error() 字符串的方法。任何实现这个接口的类型都可以作为一个错误使用。这个方法提供了对错误的描述。当打印错误时,fmt.Println 函数在内部调用 Error() 方法来获取错误的描述。这就是错误描述是如何在一行中打印出来的。
# 4. 获取错误信息
既然我们知道错误是一种接口类型,那么让我们看看如何提取更多关于错误的信息。
在上面的例子中,我们仅仅是打印了错误的描述。如果我们想要的是导致错误的文件的实际路径。一种可能的方法是解析错误字符串。这是我们程序的输出:
open /test.txt: No such file or directory
我们可以解析这个错误消息并从中获取文件路径 "/test.txt"。但这是一个糟糕的方法。在新版本的语言中,错误描述可能随时更改,我们的代码将会中断。
是否有办法可靠地获取文件名?答案是肯定的,它可以做到,Go 标准库使用不同的方式提供更多关于错误的信息。
# 4.1 断言底层结构类型并从结构字段获取更多信息
如果仔细阅读 Open() 函数的文档,可以看到它返回的是 PathError 类型的错误。

PathError 是一个 struct 类型,它在标准库中的实现如下:
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }
从上面的代码中,我可以理解 PathError 通过声明 Error() string 方法实现了错误接口。该方法连接操作、路径和实际错误并返回它。这样我们就得到了错误信息:
open /test.txt: No such file or directory
PathError 结构的路径字段包含导致错误的文件的路径。让我们修改上面写的程序,并打印出路径。
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/test.txt")
if err, ok := err.(*os.PathError); ok {
fmt.Println("File at path", err.Path, "failed to open")
return
}
fmt.Println(f.Name(), "opened successfully")
}
在上面的程序中,我们使用类型断言获得错误接口的基本值。然后自定义错误输出:
File at path /test.txt failed to open
# 4.2 断言底层数据结构并使用方法获取更多信息
获得更多信息的第二种方法是断言底层类型,并通过调用struct 类型的方法获取更多信息。
如下 DNSError:
type DNSError struct {
...
}
func (e *DNSError) Error() string {
...
}
func (e *DNSError) Timeout() bool {
...
}
func (e *DNSError) Temporary() bool {
...
}
从上面的代码中可以看到,DNSErrorstruct 有两个方法 Timeout() bool 和 Temporary() bool,它们返回一个布尔值,表示错误是由于超时还是临时的。
让我们编写一个断言 DNSError 类型的程序,并调用这些方法来确定错误是临时的还是超时的。
package main
import (
"fmt"
"net"
)
func main() {
addr, err := net.LookupHost("golangbot123.com")
// 断言错误类型
if err, ok := err.(*net.DNSError); ok {
if err.Timeout() {
fmt.Println("operation timed out")
} else if err.Temporary() {
fmt.Println("temporary error")
} else {
fmt.Println("generic error: ", err)
}
return
}
fmt.Println(addr)
}
在上面的程序中,我们正在尝试获取一个无效域名的 IP 地址,这是一个无效的域名:golangbot123.com。
在我们的例子中,错误既不是暂时的,也不是由于超时,因此程序会打印出来:
generic error: lookup golangbot123.com: no such host
# 二、Golang panic & recover
Golang 中引入两个内置函数 panic 和 recover 来触发和终止异常处理流程,同时引入关键字 defer 来延迟执行 defer 后面的函数。
# 1. panic & recover
当程序运行时,如果遇到引用空指针、下标越界或显式调用 panic 函数等情况,则先触发 panic 函数的执行,然后调用 defer 延迟函数。调用者继续传递 panic。因此该过程一直在调用栈中重复发生:函数停止执行,调用延迟执行函数等。如果一路在延迟函数中没有 recover 函数的调用,则会到达该协程的起点,该协程结束,然后终止其他所有协程,包括主协程(类似于 C 语言中的主线程,该协程 ID 为 1)。
panic
- 内建函数
- 假如函数 F 中书写了 panic 语句,会终止其后要执行的代码,在 panic 所在函数F内如果存在要执行的 defer 函数列表,按照 defer 的逆序执行;
- 返回函数 F 的调用者 G,在 G 中,调用函数 F 语句之后的代码不会执行,假如函数 G 中存在要执行的 defer 函数列表,按照 defer 的逆序执行,这里的 defer 有点类似 try-catch-finally 中的 finally;
- 直到 goroutine 整个退出,并报告错误
recover
- 内建函数
- 用来控制一个 goroutine 的 panicking 行为,捕获 anic,从而影响应用的行为
- 一般的调用建议
- 在 defer 函数中,通过 recever 来终止一个 goroutine 的 panicking 过程,从而恢复正常代码的执行
- 可以获取通过 panic 传递的 error
Golang 错误和异常是可以互相转换的:
- 错误转异常:比如程序逻辑上尝试请求某个 URL,最多尝试三次,尝试三次的过程中请求失败是错误,尝试完第三次还不成功的话,失败就被提升为异常了。
- 异常转错误:比如 panic 触发的异常被 recover 恢复后,将返回值中 error 类型的变量进行赋值,以便上层函数继续走错误处理流程。
所以什么情况下用错误表达,什么情况下用异常表达,就得有一套规则,否则很容易出现一切皆错误或一切皆异常的情况。
以下给出异常处理的作用域(场景):
- 空指针引用
- 下标越界
- 除数为0
- 不应该出现的分支,比如 default
- 输入不应该引起函数错误
其他场景我们使用错误处理,这使得我们的函数接口很精炼。对于异常,我们可以选择在一个合适的上游去 recover,并打印堆栈信息,使得部署后的程序不会终止。
说明: Golang错误处理方式一直是很多人诟病的地方,有些人吐槽说一半的代码都是 "if err != nil { / 打印 && 错误处理 / }",严重影响正常的处理逻辑。当我们区分错误和异常,根据规则设计函数,就会大大提高可读性和可维护性。
# 2. goroutine 与 panic、recover 的小问题
本小节选自:《Go语言编程之旅:一起用Go做项目》。
观察下面这段代码,思考一下其输出的结果是以下哪一个?
- “Go 编程之旅:一起用 Go 做项目”
- 因为“煎鱼焦了”而直接中断运行
package main
import "log"
func main() {
go func() {
panic("煎鱼焦了")
}()
log.Println("Go 编程之旅:一起用 Go 做项目")
}
输出:
panic: 煎鱼焦了
goroutine 18 [running]:
main.main.func1()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:7 +0x39
created by main.main
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:6 +0x35
程序因为“煎鱼焦了”而中断运行。
这时候经常会有人提出一个疑问,即 panic 语句是写在子协程里的,为何会影响外面的主协程呢?它们应该是相互隔离的,为何会互相影响呢?
# 2.1 如何解决上述问题
对于 panic 事件,我们应使用组合方法 recover 来进行处理,代码如下:
package main
import "log"
func main() {
go func() {
if e := recover(); e != nil {
log.Printf("recover: %v", e)
}
panic("煎鱼焦了")
}()
log.Println("Go 编程之旅:一起用 Go 做项目")
}
输出:
panic: 煎鱼焦了
goroutine 6 [running]:
main.main.func1()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:10 +0xa5
created by main.main
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:6 +0x35
但是仅仅使用 recover,仍然会输出“煎鱼焦了”,并且程序中断。正确的写法如下:
package main
import "log"
func main() {
go func() {
defer func() {
if e := recover(); e != nil {
log.Printf("recover: %v", e)
}
}()
panic("煎鱼焦了")
}()
log.Println("Go 编程之旅:一起用 Go 做项目")
}
实际上,recover 要与 defer 联用,并且 不跨协程 ,才能真正地拦截 panic 事件。其最终的输出结果如下:
2021/07/22 16:32:37 Go 编程之旅:一起用 Go 做项目
2021/07/22 16:32:37 recover: 煎鱼焦了
# 2.2 为什么要先 defer 才能 recover
从前文中我们知道,除 panic 和 recover 外,还必须要有 defer 关键字,三者缺一不可。为什么必须有 defer,recover 才能起作用呢?
2.2.1 快速了解 panic
panic 是 Go 语言中的一个内置函数,可以停止程序的控制流,改变其流转,并且触发“恐慌”事件。
recover 也是一个内置函数,其功能与 panic 相反,recover 可以让程序重新获取“恐慌”事件后的程序控制权,但是 recover 必须在 defer 中才会生效。
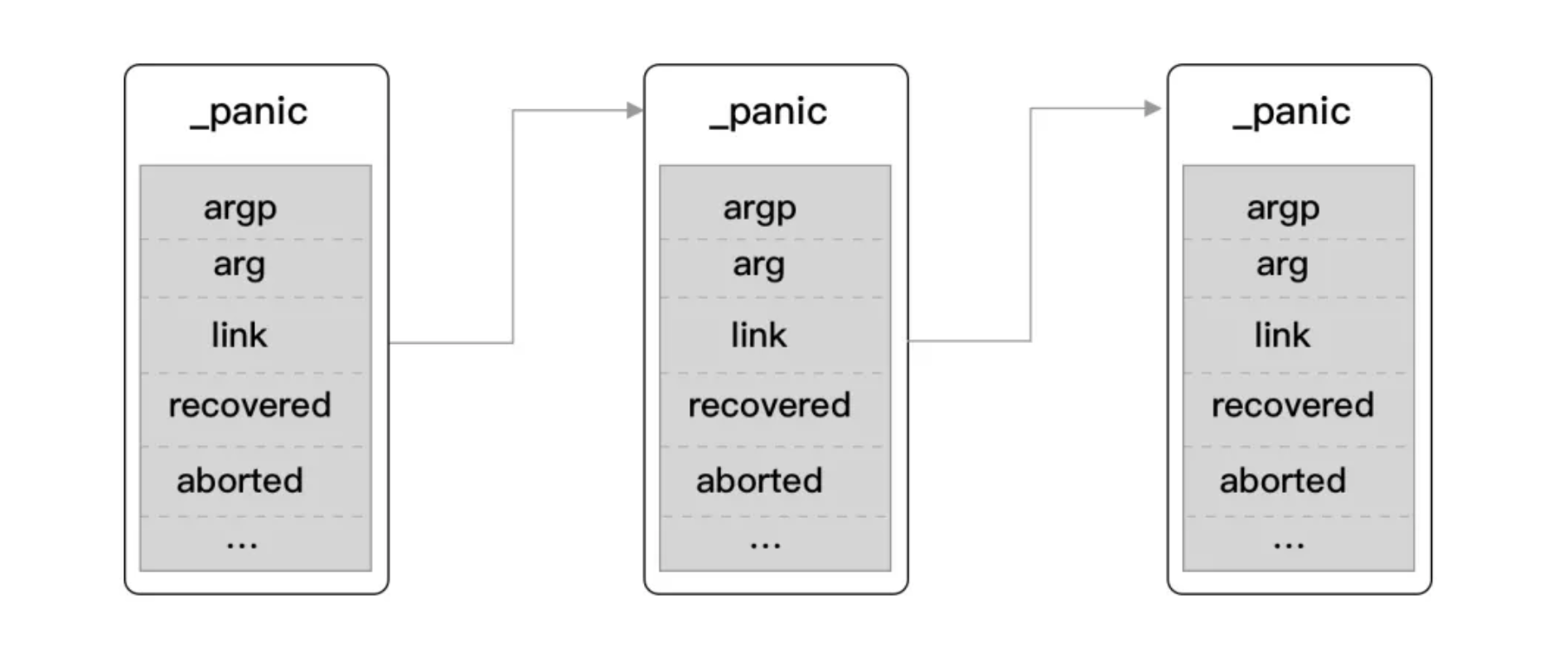
panic 的一切都基于一个 _panic 基础单元,基本结构如下:
// A _panic holds information about an active panic.
//
// A _panic value must only ever live on the stack.
//
// The argp and link fields are stack pointers, but don't need special
// handling during stack growth: because they are pointer-typed and
// _panic values only live on the stack, regular stack pointer
// adjustment takes care of them.
type _panic struct {
argp unsafe.Pointer // pointer to arguments of deferred call run during panic; cannot move - known to liblink
arg interface{} // argument to panic
link *_panic // link to earlier panic
pc uintptr // where to return to in runtime if this panic is bypassed
sp unsafe.Pointer // where to return to in runtime if this panic is bypassed
recovered bool // whether this panic is over
aborted bool // the panic was aborted
goexit bool
}
我们每执行一次 panic 语句,就会创建一个 _panic 基础单元。它包含了一些基础的字段,用于存储当前的 panic 调用情况,涉及的字段如下:
argp:指向defer延迟调用的参数的指针arg:panic的原因,即调用panic时传入的参数link:指向上一个调用的_panicpc:程序计数器,有时也称为指令指针(IP),线程利用它来跟踪下一个要执行的指令。在大多数处理器中,PC 指向的是下一条指令,而不是当前指令sp:函数栈指针寄存器,一般指向当前函数栈的栈顶recovered:panic是否已经被处理,即是否被recoveraborted:panic是否被中止goexit:是否调用runtime.Goexit方法中止主goroutine及所属的goroutine
通过查看 link 字段,可以得知,panic 的基本单元是一个链表的数据结构,如下图:
2.2.2 快速了解 defer
defer 是 Go 语言中的一个内置函数,defer 方法所注册的对应事件会在函数或方法结束后执行,常用于关闭各类资源以及“兜底”操作。
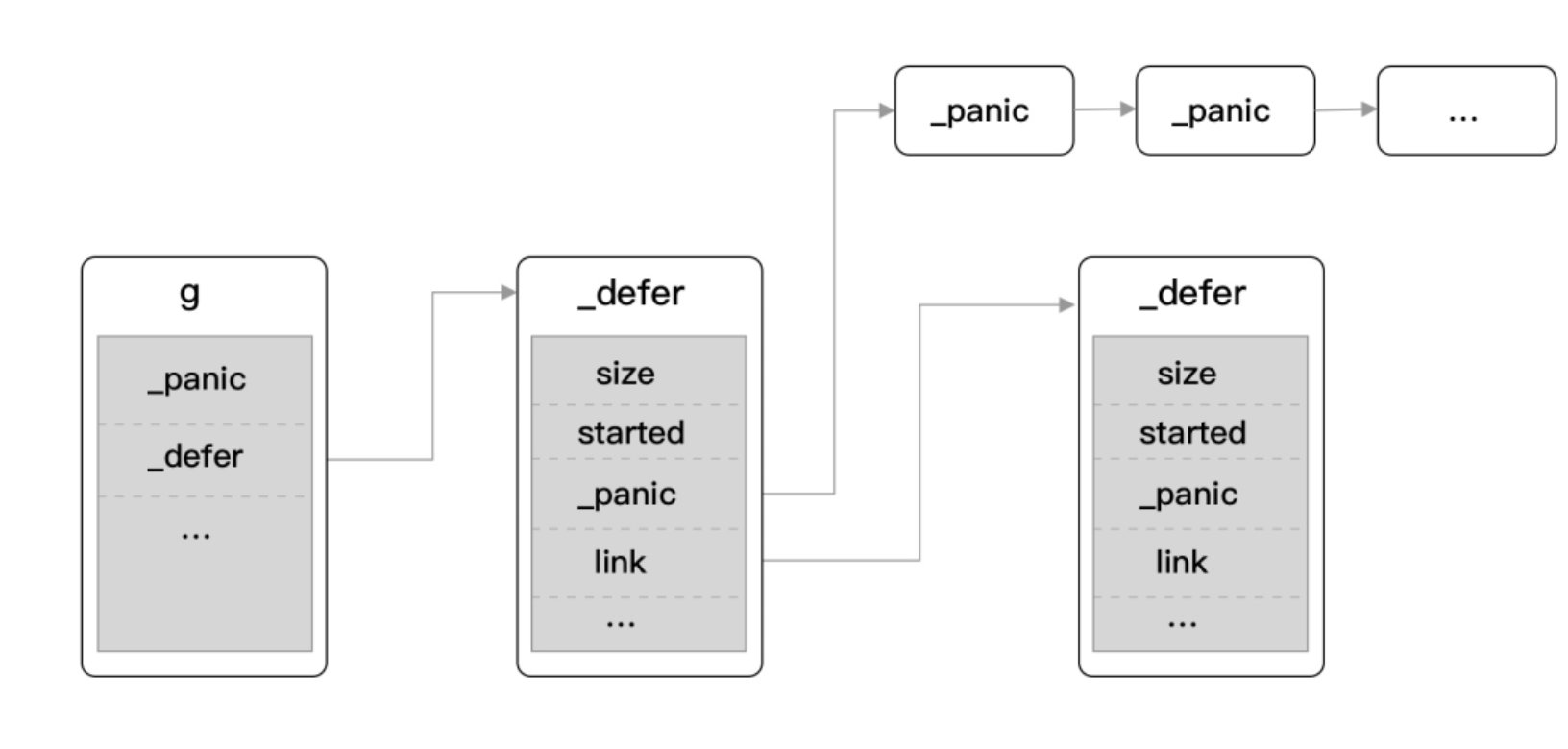
defer 的基础单元是 _defer 结构体,基本结构如下:
// A _defer holds an entry on the list of deferred calls.
// If you add a field here, add code to clear it in freedefer and deferProcStack
// This struct must match the code in cmd/compile/internal/reflectdata/reflect.go:deferstruct
// and cmd/compile/internal/gc/ssa.go:(*state).call.
// Some defers will be allocated on the stack and some on the heap.
// All defers are logically part of the stack, so write barriers to
// initialize them are not required. All defers must be manually scanned,
// and for heap defers, marked.
type _defer struct {
siz int32 // includes both arguments and results
started bool
heap bool
// openDefer indicates that this _defer is for a frame with open-coded
// defers. We have only one defer record for the entire frame (which may
// currently have 0, 1, or more defers active).
openDefer bool
sp uintptr // sp at time of defer
pc uintptr // pc at time of defer
fn *funcval // can be nil for open-coded defers
_panic *_panic // panic that is running defer
link *_defer
// If openDefer is true, the fields below record values about the stack
// frame and associated function that has the open-coded defer(s). sp
// above will be the sp for the frame, and pc will be address of the
// deferreturn call in the function.
fd unsafe.Pointer // funcdata for the function associated with the frame
varp uintptr // value of varp for the stack frame
// framepc is the current pc associated with the stack frame. Together,
// with sp above (which is the sp associated with the stack frame),
// framepc/sp can be used as pc/sp pair to continue a stack trace via
// gentraceback().
framepc uintptr
}
siz:所有传入参数的总大小started:该defer是否已经执行过sp:函数栈指针寄存器pc:程序计数器fn:指向传入的函数地址和参数_panic:指向_panic链表link:指向_defer链表
通过查看 _panic 和 link 字段可以得知,defer 同时挂载着 panic 信息,如下图:

2.2.3 recover 是如何和 defer 搭上关系的
通过前面的介绍我们知道,defer 和 panic 存在一定的关联关系,那么 recover 又是如何与它们产生关联关系的呢?为什么不用 defer,recover 就无法生效?
为了解答这些问题,我们需要回到一切的起源 panic 才能知晓。panic 关键字的具体代码如下:
func gopanic(e interface{}) {
// 1. 获取指向当前 `goroutine` 的指针
gp := getg()
...
// 2. 初始化一个 `panic` 的基本单位 `_panic` ,用作后续的操作;
var p _panic
...
for {
// 3. 获取当前 `goroutine` 上挂载的 `_defer`;
d := gp._defer
if d == nil {
break
}
...
if d.openDefer {
...
} else {
..
if goexperiment.RegabiDefer {
...
} else {
// 4. 若当前存在 `defer` 调用,则调用 `reflectcall` 方法执行先前 `defer` 中延迟执行的代码
// 若在执行过程中需要运行 `recover` ,则调用 `gorecover` 方法;
var regs abi.RegArgs
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz), uint32(d.siz), ®s)
}
}
...
}
// 5. 调用 `preprintpanics` 方法打印所涉及的 `panic` 消息;
preprintpanics(gp._panic)
// 6. 调用 `fatalpanic` 中止应用程序,实际上是通过执行 `exit(2)` 来退出的。
fatalpanic(gp._panic)
*(*int)(nil) = 0
}
通过分析上述代码,可以大致了解其处理过程:
- 获取指向当前
goroutine的指针; - 初始化一个
panic的基本单位_panic,用作后续的操作; - 获取当前
goroutine上挂载的_defer; - 若当前存在
defer调用,则调用reflectcall方法执行先前defer中延迟执行的代码。若在执行过程中需要运行recover,则调用gorecover方法; - 调用
preprintpanics方法打印所涉及的panic消息; - 调用
fatalpanic中止应用程序,实际上是通过执行exit(2)来退出的。
recover 是如何和 defer 搭上关系的?
在调用 panic 方法后,实际上 runtime.gopanic 方法处理的是当前 goroutine 上所挂载的 _panic 链表(所以无法响应其他 goroutine 的异常事件),然后对其所属的 defer 链表和 recover 进行检测并处理,最后调用退出命令中止应用程序。
如图:
从代码实现来看,panic 会触发延迟调用(defer)。假设当前 goroutine 中不存在 defer,则会直接跳出,也就无法进行 recover 了。也就是说,在 panic 时,Go 只会在 defer 中对 reocver 进行检测。
从设计实现来看,这是相对合理的,因为没有必要在程序中写若干个 recover,而很多错误是无法预料在哪里发生,又是如何发生的。
# 2.3 recover 是万能的吗
事实上,即使有了 recover,也做不到捕获所有的错误。
假设某一天,程序正在线上环境(容器里)运行着,突然就“挂”了,即它反复地重启,且每次都是运行一段时间后才宕机,难道有泄露了?
这个程序非常的简短,就是一段简单的并发清洗、组装数据的程序,核心(伪)代码如下:
package main
import (
"log"
"time"
)
func main() {
m := make(map[int]string)
for i := 0; i < 10; i++ {
go func() {
defer func() {
if e:= recover(); e != nil {
log.Printf("recover: %v", e)
}
}()
m[i] = "Go 编程之旅:一起用 Go 做项目"
}()
}
time.Sleep(5 * time.Second)
}
输出:
fatal error: concurrent map writes
goroutine 19 [running]:
runtime.throw(0x10ce7ac, 0x15)
/usr/local/go/src/runtime/panic.go:1117 +0x72 fp=0xc000044f50 sp=0xc000044f20 pc=0x10327f2
runtime.mapassign_fast64(0x10b5ce0, 0xc000098180, 0x3, 0x0)
/usr/local/go/src/runtime/map_fast64.go:101 +0x33e fp=0xc000044f90 sp=0xc000044f50 pc=0x1010c3e
main.main.func1(0xc000098180, 0xc0000b6008)
通过错误信息我们可以得知,这是一个十分常见的问题,就是 并发写入 map 导致的致命错误。为什么 recover 没有捕获到呢?先来看看 runtime.throw 方法,代码如下:
//go:nosplit
func throw(s string) {
// Everything throw does should be recursively nosplit so it
// can be called even when it's unsafe to grow the stack.
systemstack(func() {
print("fatal error: ", s, "\n")
})
gp := getg()
if gp.m.throwing == 0 {
gp.m.throwing = 1
}
fatalthrow()
*(*int)(nil) = 0 // not reached
}
//go:nosplit
nosplit 指令是用于指定文件中声明的下一个函数不得包含堆栈溢出检查(简单来讲,就是这个函数跳过堆栈溢出的检查。)。在不安全地抢占调用 goroutine 的时间调用的低级运行时源最常使用此方法。
关键的中断步骤在 fatalthrow 方法中,代码如下:
// fatalthrow implements an unrecoverable runtime throw. It freezes the
// system, prints stack traces starting from its caller, and terminates the
// process.
//go:nosplit
func fatalthrow() {
pc := getcallerpc()
sp := getcallersp()
gp := getg()
// Switch to the system stack to avoid any stack growth, which
// may make things worse if the runtime is in a bad state.
systemstack(func() {
startpanic_m()
if dopanic_m(gp, pc, sp) {
// crash uses a decent amount of nosplit stack and we're already
// low on stack in throw, so crash on the system stack (unlike
// fatalpanic).
crash()
}
exit(2)
})
*(*int)(nil) = 0 // not reached
}
可以看到,该方法是直接通过调用 exit 方法进行中断的。实际上在 Go 语言中,是存在着一些无法恢复的“恐慌”事件的,如 fatalthrow 方法、fatalpanic 方法等。
由此可见,recover 并非万能的,它只对用户态下的 panic 关键字有效。
# 3. 让 Go “恐慌”的十种方法
本小节选自:《Go语言编程之旅:一起用Go做项目》。
① 数组/切片越界访问
func main() {
names := []string{
"煎鱼",
"eddycjy",
"Go编程之旅",
}
name := names[len(names)]
fmt.Printf("name: %s", name)
}
运行结果:
panic: runtime error: index out of range [3] with length 3
goroutine 1 [running]:
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:13 +0x1b
② 空指针调用
type User struct {
Name string
}
func (u *User) GetName() string {
return u.Name
}
func main() {
s := &User{Name: "煎鱼"}
s = nil
s.GetName()
}
运行结果:
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x105e262]
goroutine 1 [running]:
main.(*User).GetName(...)
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:8
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:14 +0x2
③ 过早关闭 HTTP 响应体
func main() {
resp, err := http.Get("https://xxx")
defer resp.Body.Close()
if err != nil {
log.Fatalf("http.Get err: %v", err)
}
}
运行结果:
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x40 pc=0x1233808]
goroutine 1 [running]:
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:10 +0x68
④ 除以零
unc divide(a, b int) int {
return a / b
}
func main() {
divide(1, 0)
}
运行结果:
panic: runtime error: integer divide by zero
goroutine 1 [running]:
main.divide(...)
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:4
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:8 +0x12
⑤ 向已关闭的通道发送消息
func main() {
ch := make(chan string, 1)
ch <- "煎鱼"
close(ch)
ch <- "Go编程之旅"
}
运行结果:
panic: send on closed channel
goroutine 1 [running]:
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:7 +0x7f
⑥ 重复关闭通道
func main() {
ch := make(chan string, 1)
ch <- "Go编程之旅"
close(ch)
close(ch)
}
运行结果:
panic: close of closed channel
goroutine 1 [running]:
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:7 +0x73
⑦ 关闭未初始化通道
func main() {
var ch chan string
close(ch)
}
运行结果:
panic: close of nil channel
goroutine 1 [running]:
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:5 +0x2a
⑧ 未初始化 map
func main() {
var m map[string]string
m["Go编程之旅"] = "一起用Go做项目"
}
运行结果:
panic: assignment to entry in nil map
goroutine 1 [running]:
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:5 +0x4b
⑨ 跨协程“恐慌”处理
func main() {
go func() {
defer func() {
if err := recover(); err != nil {
log.Fatalf("recover err: %v", err)
}
}()
handle()
}()
time.Sleep(time.Second)
}
func handle() {
go divide(1, 0)
}
func divide(a, b int) int {
return a / b
}
运行结果:
panic: runtime error: integer divide by zero
goroutine 17 [running]:
main.divide(0x1, 0x0, 0x0)
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:26 +0x46
created by main.handle
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:22 +0x47
⑩ sync 计数为负数
func main() {
wg := sync.WaitGroup{}
wg.Add(-1)
wg.Wait()
}
运行结果:
panic: sync: negative WaitGroup counter
goroutine 1 [running]:
sync.(*WaitGroup).Add(0xc0000160c0, 0xffffffffffffffff)
/usr/local/go/src/sync/waitgroup.go:74 +0x147
main.main()
/Users/bytedance/go/src/baiscstudy/learning/exception/error/error.go:9 +0x49
# 三、Golang 错误和异常正确处理
本小节参考:https://studygolang.com/articles/11753
# 1. 错误处理的正确姿势
① 失败的原因只有一个时,不使用 error
func (self *AgentContext) CheckHostType (host_type string) error {
switch host_type {
case "virtual_machine":
return nil
case "bare_metal":
return nil
}
return errors.New("CheckHostType ERROR:" + host_type)
}
我们可以看出,该函数失败的原因只有一个,所以返回值的类型应该为 bool,而不是 error,重构一下代码:
func (self *AgentContext) IsValidHostType(hostType string) bool {
return hostType == "virtual_machine" || hostType == "bare_metal"
}
大多数情况,导致失败的原因不止一种,尤其是对 I/O 操作而言,用户需要了解更多的错误信息,这时的返回值类型不再是简单的 bool,而是 error。
② 错误值统一定义,而不是跟着感觉走
很多人写代码时,到处 return errors.New(value),而错误 value 在表达同一个含义时也可能形式不同,比如“记录不存在”的错误 value 可能为:
- "record is not existed."
- "record is not exist!"
- "###record is not existed!!!"
- …
这使得相同的错误 value 撒在一大片代码里,当上层函数要对特定错误 value 进行统一处理时,需要漫游所有下层代码,以保证错误 value 统一,不幸的是有时会有漏网之鱼,而且这种方式严重阻碍了错误 value 的重构。
于是,我们可以参考 C/C++ 的错误码定义文件,在 Golang 的每个包中增加一个错误对象定义文件,如下所示:
var ERR_EOF = errors.New("EOF")
var ERR_CLOSED_PIPE = errors.New("io: read/write on closed pipe")
var ERR_NO_PROGRESS = errors.New("multiple Read calls return no data or error")
var ERR_SHORT_BUFFER = errors.New("short buffer")
var ERR_SHORT_WRITE = errors.New("short write")
var ERR_UNEXPECTED_EOF = errors.New("unexpected EOF")
③ error 应该放在返回列表的最后
对于返回值类型 error,用来传递错误信息,在 Golang 中通常放在最后一个:
resp, err := http.Get(url)
if err != nil {
return nill, err
}
bool 作为返回值类型时也一样。
④ 错误逐层递归时,层层都加日志
层层都加日志非常方便故障定位。
至于通过测试来发现故障,而不是日志,目前很多团队还很难做到。如果你或你的团队能做到,那么请忽略这个姿势。
⑤ 当尝试几次可以避免失败时,不要立即返回错误
如果错误的发生是偶然性的,或由不可预知的问题导致。一个明智的选择是重新尝试失败的操作,有时第二次或第三次尝试时会成功。在重试时,我们需要限制重试的时间间隔或重试的次数,防止无限制的重试。
两个案例:
- 我们平时上网时,尝试请求某个 URL,有时第一次没有响应,当我们再次刷新时,就有了惊喜。
- 团队的一个 QA 曾经建议当 Neutron 的 attach 操作失败时,最好尝试三次,这在当时的环境下验证果然是有效的。
⑥ 当上层函数不关系错误时,建议不返回 error
对于一些资源清理相关的函数(destroy/delete/clear),如果子函数出错,打印日志即可,而无需将错误进一步反馈到上层函数,因为一般情况下,上层函数是不关心执行结果的,或者即使关心也无能为力,于是我们建议将相关函数设计为不返回 error。
⑦ 当发生错误时,不忽略有用的返回值
通常,当函数返回 non-nil 的 error 时,其他的返回值是未定义的,这些未定义的返回值应该被忽略。然而,有少部分函数在发生错误时,仍然会返回一些有用的返回值。比如,当读取文件发生错误时,Read 函数会返回可以读取的字节数以及错误信息。对于这种情况,应该将读取到的字符串和错误信息一起打印出来。
# 2. 异常处理的正确姿势
① 在程序开发阶段,坚持速错
速错,简单来讲就是“让它挂”,只有挂了你才会第一时间知道错误。在早期开发以及任何发布阶段之前,最简单的同时也可能是最好的方法是调用 panic 函数来中断程序的执行以强制发生错误,使得该错误不会被忽略,因而能够被尽快修复。
② 在程序部署后,应恢复异常,避免程序终止
在 Golang 中,某个 Goroutine 如果 panic 了,并且没有 recover,那么整个 Golang 进程就会异常退出。所以,一旦 Golang 程序部署后,在任何情况下发生的异常都不应该导致程序异常退出,我们在上层函数中加一个延迟执行的 recover 调用来达到这个目的,并且是否进行 recover 需要根据环境变量或配置文件来定,默认需要 recover。
这个姿势类似于 C 语言中的断言,但还是有区别:一般在 Release 版本中,断言被定义为空而失效,但需要有 if 校验存在进行异常保护,尽管契约式设计中不建议这样做。在 Golang 中,recover 完全可以终止异常展开过程,省时省力。
我们在调用 recover 的延迟函数中以最合理的方式响应该异常:
- 打印堆栈的异常调用信息和关键的业务信息,以便这些问题保留可见;
- 将异常转换为错误,以便调用者让程序恢复到健康状态并继续安全运行。
我们看一个简单的例子:
package main
import (
"errors"
"fmt"
"runtime/debug"
)
func main() {
err := funcA()
if err == nil {
fmt.Printf("err is nil\n")
} else {
fmt.Printf("err is %v\n",err)
}
}
func funcA() error {
defer func() {
if p := recover(); p != nil {
fmt.Printf("panic recover! p: %v", p)
debug.PrintStack()
}
}()
return funcB()
}
func funcB() error {
// simulation
panic("foo")
return errors.New("success")
}
我们期望 test 函数输出的是:
err is foo
实际上输出的是:
err is nil
原因是 panic 异常处理机制不会自动将错误信息传递给 error,所以要在 funcA 函数中进行显式的传递,代码如下所示:
package main
import (
"errors"
"fmt"
"runtime/debug"
)
func main() {
err := funcA()
if err == nil {
fmt.Printf("err is nil\n")
} else {
fmt.Printf("err is %v\n",err)
}
}
func funcA() (err error) {
defer func() {
if p := recover(); p != nil {
fmt.Printf("panic recover! p: %v", p)
str, ok := p.(string)
if ok {
err = errors.New(str)
} else {
err = errors.New("panic")
}
debug.PrintStack()
}
}()
return funcB()
}
func funcB() error {
// simulation
panic("foo")
return errors.New("success")
}
③ 对于不应该出现的分支,使用异常处理
switch s := suit(drawCard()); s {
case "Spades":
// ...
case "Hearts":
// ...
case "Diamonds":
// ...
case "Clubs":
// ...
default:
panic(fmt.Sprintf("invalid suit %v", s))
}
④ 针对入参不应该有问题的函数,使用 panic 设计
入参不应该有问题一般指的是硬编码,我们先看这两个函数(Compile 和 MustCompile),其中 MustCompile 函数是对 Compile 函数的包装:
func MustCompile(str string) *Regexp {
regexp, error := Compile(str)
if error != nil {
panic(regexp: Compile( + quote(str) + ): + error.Error())
}
return regexp
}
所以,对于同时支持用户输入场景和硬编码场景的情况,一般支持硬编码场景的函数是对支持用户输入场景函数的包装。 对于只支持硬编码单一场景的情况,函数设计时直接使用 panic,即返回值类型列表中不会有 error,这使得函数的调用处理非常方便(没有了乏味的 "if err != nil {/ 打印 && 错误处理 /}" 代码块)。