# 1. 字符串相关的类
# 1.1 String

说明
final
String 是一个 final 类,代表不可变的字符序列,不可以被继承。
字符串是常量,用双引号引起来表示。它们的值在创建之后不能更改。
value[]
String 对象的字符内容是存储在一个字符数组 value[] 中的。
当对字符串重新赋值时,需要重新向指定内存区域赋值,不能使用原有的 value[] 进行赋值(因为数组是不可变长的)。
对现有的字符串进行拼接操作时,也需要重新分配空间。
Serializable
String 是支持序列化的。
Comparable
String 的可以比较大小的 —— 使用 String.compareTo 方法比较对应字符的大小(ASCII 码顺序)
- 如果字符串相等返回值 0;
- 如果第一个字符和参数的第一个字符不等,结束比较,返回他们之间的差值(ASCII 码值)(负值前字符串的值小于后字符串,正值前字符串大于后字符串);
- 如果第一个字符和参数的第一个字符相等,则以第二个字符和参数的第二个字符做比较,以此类推,直至比较的字符或被比较的字符有一方全比较完,这时就比较字符的长度;
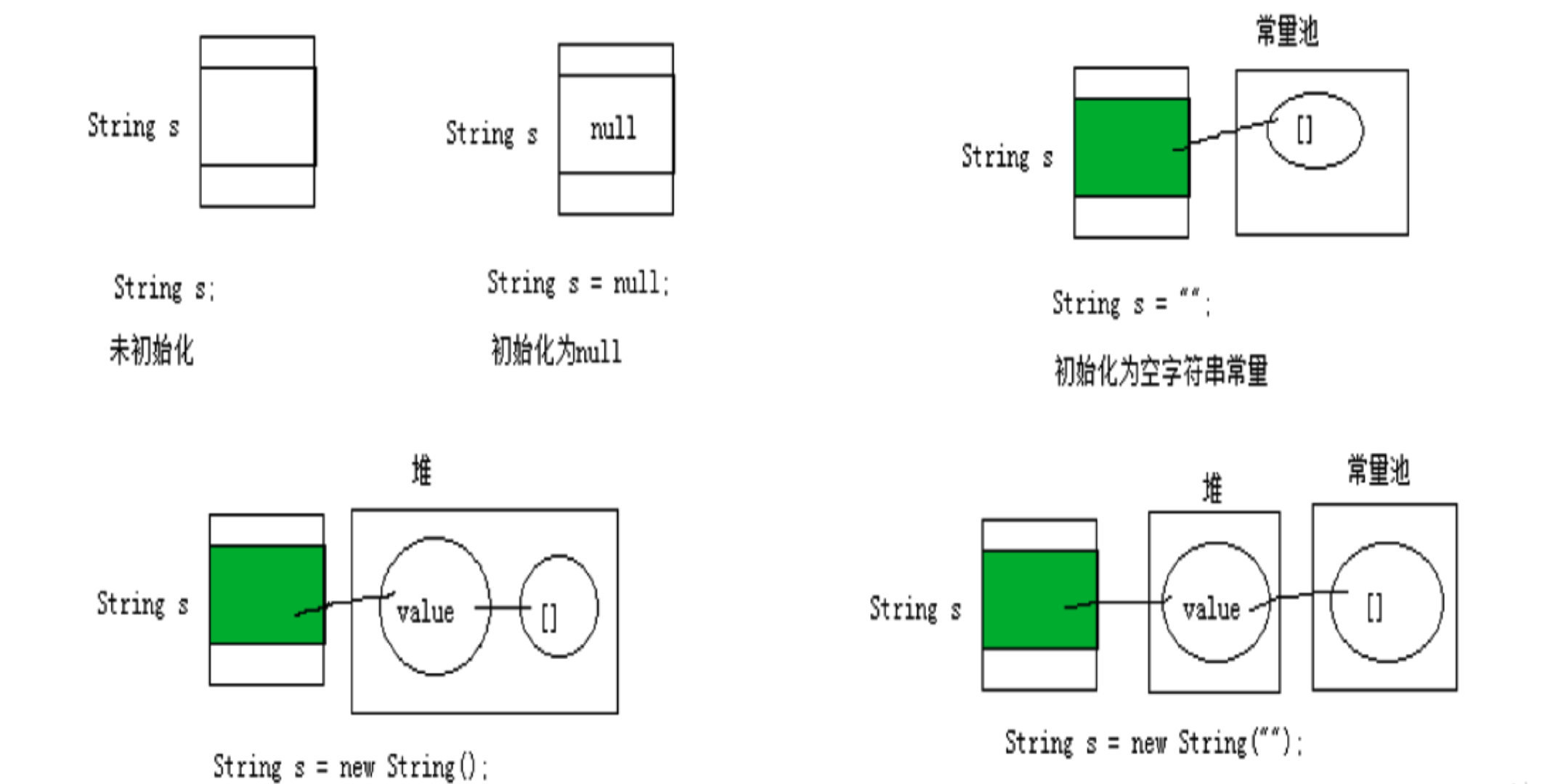
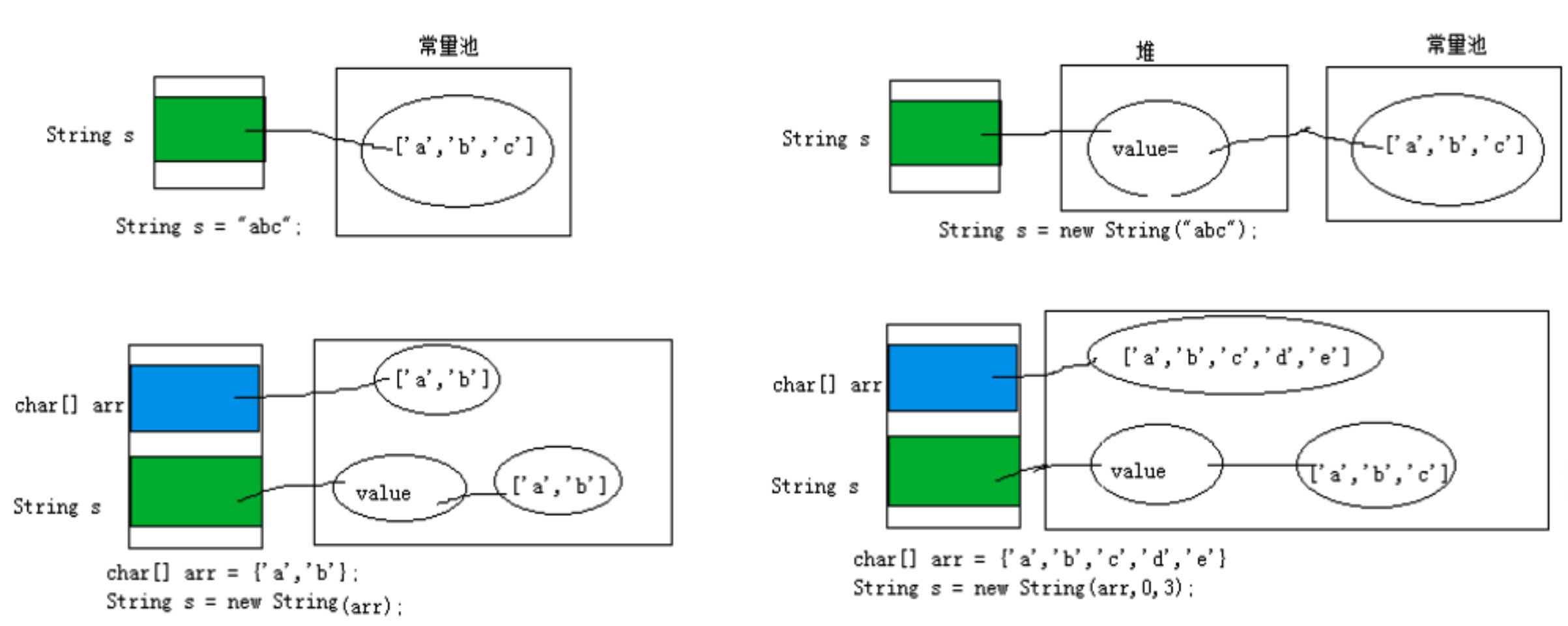
# 1.1.1 String 对象的创建
//字面上的定义,字符串常量存储在 字符串常量池,目的是共享
String str = "hello";
//本质上相当于 this.value = new char[0];
String str1 = new String();
//本质上相当于 this.value = original.value
String str2 = new String(String original);
//本质上相当于 this.value = Arrays.copyOf(value,value.length)
String str3 = new String(char[] a);
//本质上相当于 this.value = Arrays.copyOfRange(value,offset,offset+count)
String str4 = new String(char[] a, int startIndex, int count);
内存分配情况如图:
# 1.1.2 问题一:String str = "abc" 与 String str = new String("abc") 的区别
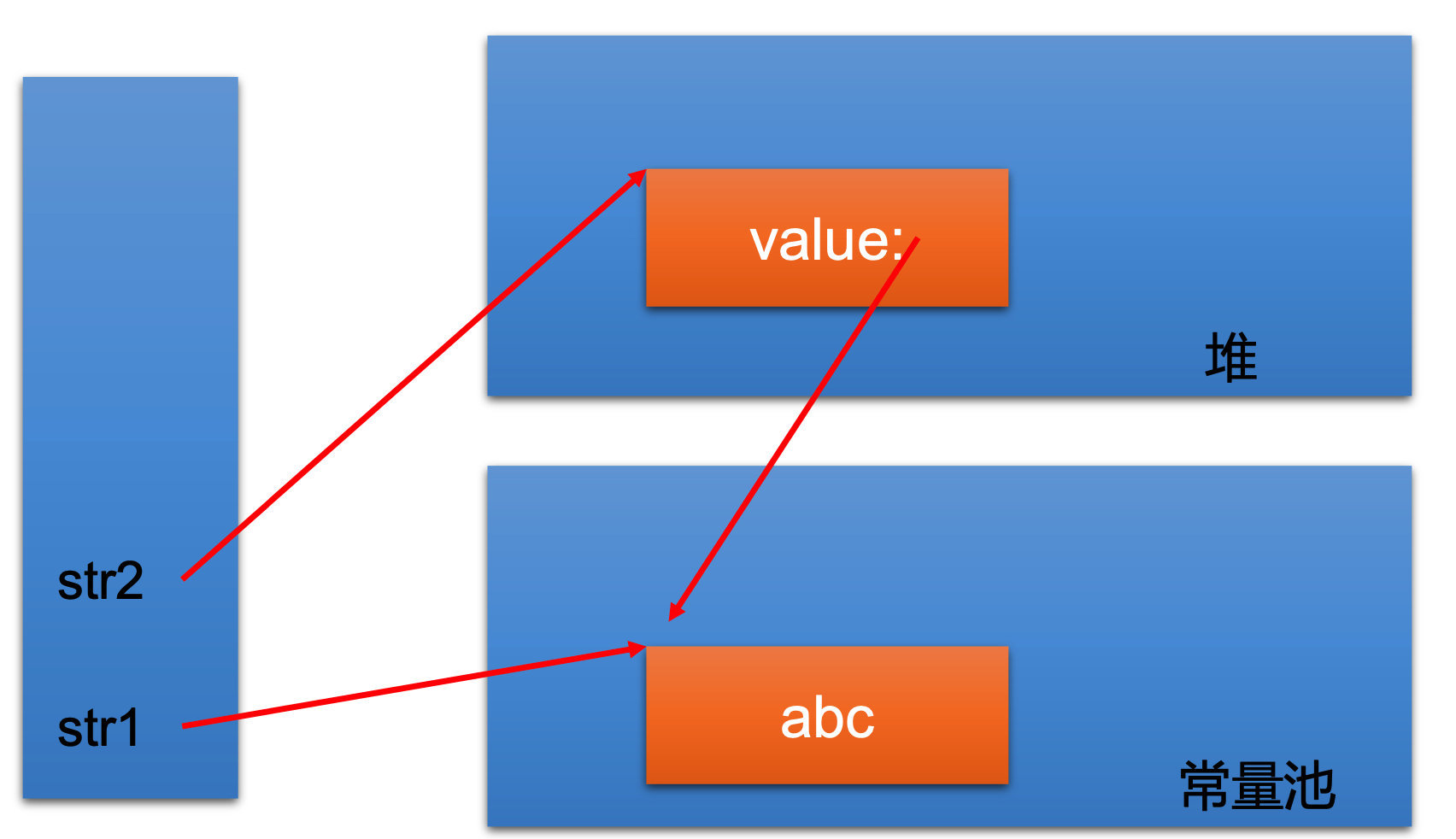
# 回答
① 字符串常量存储为了方便共享,放在字符串常量池中;
② 字符串非常量对象放在堆中(new 出来的东西都放在堆中);
③ String s = new String("abc") 在创建对象的时候,在内存中创建了 2 个对象,一个是堆空间中的 new 结构,另一个是 char[] 对应的常量池中的数据:“abc”。
# 内存分配
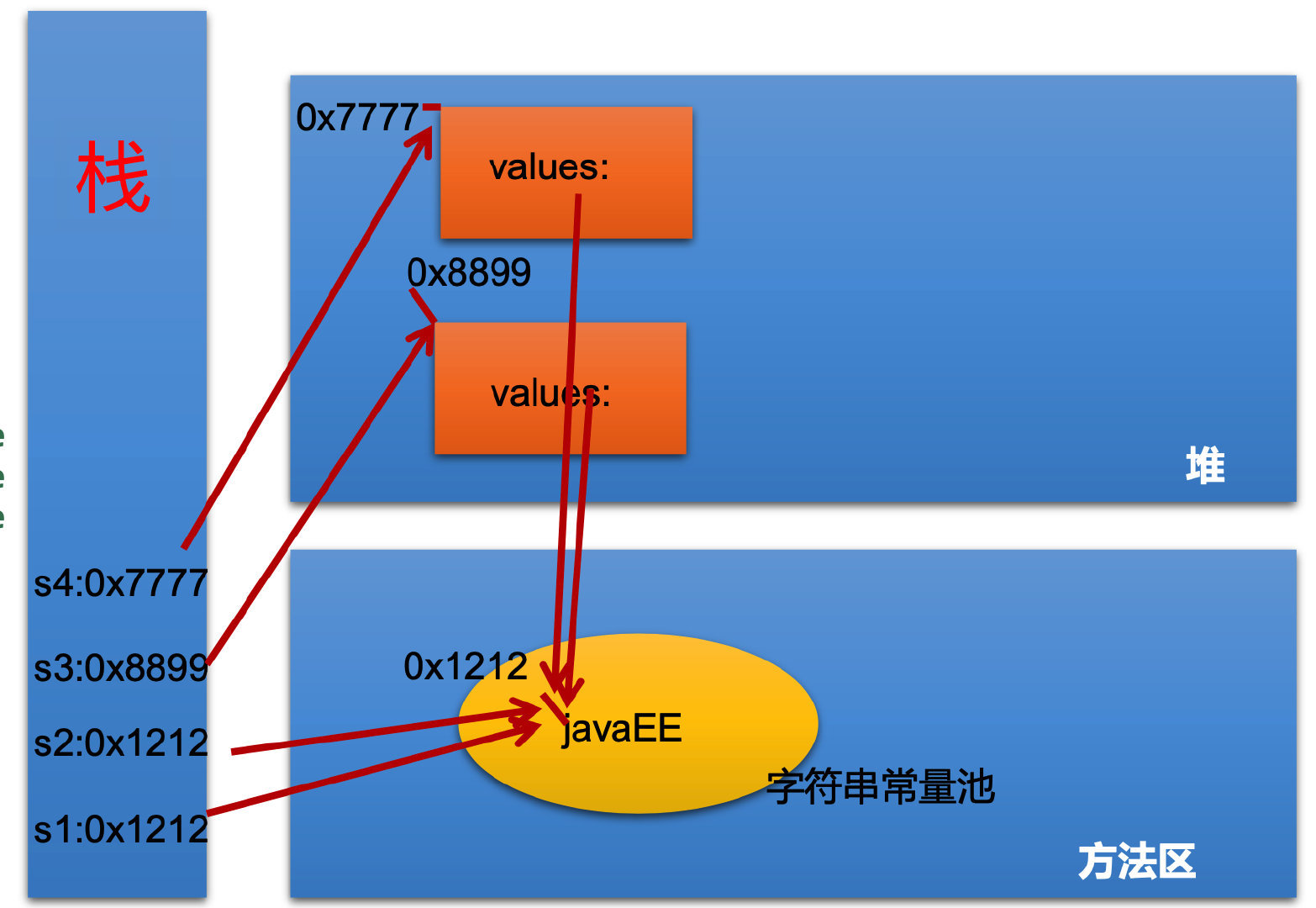
String str1 = "javaEE";
String str2 = "javaEE";
String str3 = new String("javaEE");
String str4 = new String("javaEE");
# 结论
str1 == str2 (创建 str2 的时候会去常量池找找看有没有等于 "javaEE" 的字符串,如果有就直接共用了)
str1 != str3
str3 != str4
str1.equals(str3) == true
# 如下图
# 1.1.3 问题二:对象中 String 类型的属性是如何存储的
Person p1 = new Person("hedon",21);
Person p2 = new Person("hedon",21);
System.out.println(p1.getName() == p2.getName());
System.out.println(p1.getName() == "hedon");
# 输出结果
true
true

# 图解
上述代码在为 name 属性赋值的时候,采用的是字面量的赋值方式,所以会在常量池中找是否有相同的值,如果有就指向同一个了。
但是如果是用 new String() 来进行赋值,那就会先在堆中开辟一块空间,再指向常量池中的字符串。
# 1.1.4 加深对常量池的理解
@Test
public void test2(){
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
final String s8 = "javaEE";
String s9 = s8 + "hadoop";
System.out.println(s3 == s4); //true
System.out.println(s3 == s5); //false
System.out.println(s3 == s6); //false
System.out.println(s5 == s6); //false
System.out.println(s5 == s7); //false
System.out.println(s6 == s7); //false
System.out.println(s9 == s4); //true
}
# 结论
如果只是字面量间的操作的话,那就只是在常量池玩;
如果出现了"变量名",因为变量名其实就是一个引用(地址),那么这个时候就不只是在常量池玩了,是在堆里面玩了。
# 例外
如果加了 final,那么它就是常量池里面的值。
# 1.1.5 神奇的 intern() 方法
如果调用 intern() 方法,那返回值就会放在常量池中。
@Test
public void test2(){
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
String s8 = s7.intern();
System.out.println(s8 == s3); //true
System.out.println(s8 == s7); //false
}
再看 intern() 源码:

# 源码解释
从上述源码的 @return 的解释就可以看出返回的值是放在常量池的了(pool);
# native 关键字
笔者在此之前从未见过 native 关键字,这次在这里瞅到,特地查了一下,简单来说如下:
① native 主要用在方法上;
② 一个 native 方法就是一个 Java 调用非 Java 代码的接口。一个 native 方法是指该方法的实现由非 Java 语言实现,比如用 C 或 C++ 实现;
③ 在定义一个 native 方法时,并不提供实现体(比较像定义一个 Java Interface),因为其实现体是由非 Java 语言在外面实现的;
④ Java 无法对操作系统底层进行操作,但是可以通过 JNI(java native interface) 调用其他语言来实现底层的访问;
# 参考
https://www.jianshu.com/p/429dc9aa2ce4
https://www.cnblogs.com/KingIceMou/p/7239668.html
# 1.1.6 String 的传参问题
public class StringClass {
String str = new String("java");
char[] ch = {'t','e','s','t'};
public void change(String str, char[] ch){
str = "test ok";
ch[0] = 'b';
}
public void change1(StringClass stringClass){
stringClass.str = "test ok";
stringClass.ch[0] = 'c';
}
public static void main(String[] args) {
StringClass stringClass = new StringClass();
stringClass.change(stringClass.str,stringClass.ch);
//String(基本数据类型且不可变) 在传参的时候传的是 str 的值, 方法中只是赋值给了 str 的拷贝,不会修改 str 本身
System.out.println(stringClass.str); //java
//char[0] 表示的是一个地址,修改的时候是修改地址指向的值,所以会变
System.out.println(stringClass.ch); //best
//stringClass(引用数据类型) 传的是引用, 会修改真正的值
stringClass.change1(stringClass);
System.out.println(stringClass.str); //test ok
System.out.println(stringClass.ch); //cest
}
}
# 1.1.7 常用方法
# int length()
返回字符串的长度: return value.length
# char charAt(int index)
返回某索引处的字符return value[index]
# boolean isEmpty()
判断是否是空字符串:return value.length == 0
# String toLowerCase()
使用默认语言环境,返回 String 中的所有字符转换为小写的字符串,原字符串不变
# String toUpperCase()
使用默认语言环境,返回 String 中的所有字符转换为大写的字符串,原字符串不变
# String trim()
返回字符串的副本,忽略前导空白和尾部空白,原字符串不变
# boolean equals(Object obj)
比较字符串的内容是否相同
# boolean equalsIgnoreCase(String anotherString)
与equals方法类似,忽略大小写
# String concat(String str)
将指定字符串连接到此字符串的结尾。 等价于用“+”
# int compareTo(String anotherString)
比较两个字符串的大小
# String substring(int beginIndex)
返回一个新的字符串,它是此字符串的从 beginIndex 开始截取到最后的一个子字符串。
# String substring(int beginIndex, int endIndex)
返回一个新字符串,它是此字符串从 beginIndex 开始截取到 endIndex (不包含)的一个子字符串
# boolean endsWith(String suffix)
测试此字符串是否以指定的后缀结束
# boolean startsWith(String prefix)
测试此字符串是否以指定的前缀开始
# boolean startsWith(String prefix, int toffset)
测试此字符串从指定索引开始的子字符串是否以指定前缀开始
# boolean contains(CharSequence s)
当且仅当此字符串包含指定的 char 值序列 时,返回 true
# int indexOf(String str)
返回指定子字符串在此字符串中第一次出现处的索引
# int indexOf(String str, int fromIndex)
返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始
# int lastIndexOf(String str)
返回指定子字符串在此字符串中最右边出现处的索引
# int lastIndexOf(String str, int fromIndex)
返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索
`注:indexOf和lastIndexOf方法如果未找到都是返回-1`
# String replace(char oldChar, char newChar)
返回一个新的字符串,它是 通过用 newChar 替换此字符串中出现的所有 oldChar 得到的
# String replace(CharSequence target, CharSequence replacement)
使用指定的字面值替换序列替换此字符串所有匹配字面值目标序列的子字符串
# String replaceAll(String regex, String replacement)
使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串
# String replaceFirst(String regex, String replacement)
使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串
# boolean matches(String regex)
告知此字符串是否匹配给定的正则表达式
# String[] split(String regex)
根据给定正则表达式的匹配拆分此字符串
# String[] split(String regex, int limit)
根据匹配给定的正则表达式来拆分此字符串,最多不超过 limit 个,如果超过了,剩下的全部都放到最后一个元素中
# 1.1.8 数据类型转换
# String -> 数字
int i = Integer.parseInt("134");
double d = Double.parseDouble("134.5");
float f = Float.parseFloat("134.5");
long l = Long.parseLong("12345");
# 数字-> String
String s = String.valueOf(1);
String a = String.valueOf('a');
String s1 = String.valueOf(1.1);
String s2 = String.valueOf(false); //s2="false"
String s3 = "" + 1;
# 字符数组 -> 字符串
char[] a = {'a','b','c'};
String s = new String(a);
# 字符串 -> 字符数组
//public char[] toCharArray()
char[] a = {'a','b','b'};
String s = new String(a);
//public void getChars(int srcBegin, int srcEnd, char[] dst,int dstBegin)
String s = "hedon";
char[] c1 = new char[10];
//参数1:从 s 的第几位开始取(包含)
//参数2:到 s 的第几位停止取(不包含)
//参数3:取出来的字符放到哪个字符数组中
//参数4:从字符数组的第几个位置开始放从 s 取出来的字符
s.getChars(1,3,c1,3);
# 字节数组 -> 字符串
byte[] b = {0x11,0x22,0x33,0x44};
for (int i = 0; i < b.length; i++) {
System.out.println(b[i]); //17 34 51 68
}
//通过使用平台的默认字符集解码指定的 byte 数组,构造一个新的 String
String s1 = new String(b);
System.out.println(s1); // "3D
//用指定的字节数组的一部分, 即从数组起始位置offset开始取length个字节构造一个字符串对象
String s2 = new String(b,1,2);
System.out.println(s2); //"3
# 字符串 -> 字符数组
String s = "hedon";
//使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中
byte[] b1 = s.getBytes();
for (int i = 0; i < b1.length; i++) {
System.out.println(b1[i]); //-128~127 => 104 101 100 111 110
}
String s2 = "哈哈哈哈";
//使用指定的字符集将 此 String 编码到 byte 序列,并将结果存储到新的 byte 数组
byte[] b2 = s2.getBytes("UTF-8");
System.out.println(b2.length); //-128~127 => 12
byte[] b3 = s2.getBytes("ISO8859-1"); //乱码,表示不了中文
System.out.println(b3); // [B@3581c5f3
# 1.2 StringBuffer
# 1.2.1 简介
java.lang.StringBuffer 代表可变的字符序列,在 JDK1.0 中声明,它可以对字符串内容进行增删,此时不会产生新的对象;

很多方法与 String 相同;
作为参数传递时,方法内部可以改变值;

# 1.2.2 StringBuffer 对象的创建
StringBuffer 类不同于 String,其对象必须使用构造器生成。有三个构造器:
StringBuffer():初始容量为 16 的字符串缓冲区
public StringBuffer() { super(16); }StringBuffer(int capacity):构造指定容量的字符串缓冲区
public StringBuffer(int capacity) { super(capacity); }StringBuffer(String str):将内容初始化为指定字符串内容,容量为 str.length+16
public StringBuffer(String str) { super(str.length() + 16); append(str); }StringBuffer stringBuffer = new StringBuffer("hedon"); int capacity = stringBuffer.capacity(); System.out.println(capacity); //21 int length = stringBuffer.length(); System.out.println(length); //5
# 1.2.3 常用方法
# StringBuffer append(xxx)
提供了很多的append()方法,用于进行字符串拼接
# StringBuffer delete(int start,int end)
删除指定位置的内容
# StringBuffer replace(int start, int end, String str)
把[start,end)位置替换为str
# StringBuffer insert(int offset, xxx)
在指定位置插入xxx
# StringBuffer reverse()
把当前字符序列逆转
# public int indexOf(String str)
返回指定子字符串首次出现在该字符串中的索引
# public String substring(int start,int end)
返回 [start,end) 子串
# public char charAt(int n )
在指定的索引处按此序列返回char值
# public void setCharAt(int n ,char ch)
将指定位置的字符替换为 ch
# public int capaticy()
返回容量
# public int length()
返回有效字符的长度
# 1.3 StringBuidler
StringBuilder 和 StringBuffer 非常类似,均代表可变的字符序列。而且提供相关功能的方法也一样
# 1.4 JVM 中字符串常量池存放位置说明
# 1.6
字符串常量池存放在方法区(永久区);
# 1.7
字符串常量池存储在堆空间;
# 1.8
字符串常量池存储在方法区(元空间);
# △ 面试题
# 1. String、StringBuffer、StringBuilder 的区别
# 可变与否
String 为不可变字符序列;StringBuffer 和 StringBuilder 均为可变字符序列;
# 拼接效率
StringBuilder > StringBuffer > String
@Test
public void test(){
String string = null ;
StringBuffer stringBuffer = new StringBuffer();
StringBuilder stringBuilder = new StringBuilder();
long startTime1 = System.currentTimeMillis();
for(int i=1;i<=100000;i++){
string =string+String.valueOf(i);
}
long endTime1=System.currentTimeMillis();
System.out.println("使用String实现循环,程序运行时间为:"+(endTime1-startTime1)+"毫秒"); //17662
long startTime2 = System.currentTimeMillis();
for(int i=1;i<=100000;i++){
stringBuffer =stringBuffer.append(i);
}
long endTime2=System.currentTimeMillis();
System.out.println("使用StringBuffer实现循环,程序运行时间为:"+(endTime2-startTime2)+"毫秒"); //5
long startTime3 = System.currentTimeMillis();
for(int i=1;i<=100000;i++){
stringBuilder =stringBuilder.append(i);
}
long endTime3=System.currentTimeMillis();
System.out.println("使用stringBuilder实现循环,程序运行时间为:"+(endTime3-startTime2)+"毫秒"); //4
}
# 线程安全是否
String 线程安全(所有不可变类都是线程安全的);
StringBuffer 线程安全;
StringBuilder 线程不安全。
# 传参问题
作为参数传递的话,方法内部 String 不会改变其值,StringBuffer 和 StringBuilder 会改变其值。
# 2. 为什么说 StringBuilder 是线程不安全的而 StringBuffer 是线程安全的
参考:https://blog.csdn.net/u010982507/article/details/102381834
PS:上述参考的博主写的非常好,但是笔者在分析数组越界问题上与其有些许不同的见解,还请批评指导。
# StringBuilder
测试 StringBuilder
public static void main(String[] args) { StringBuilder sb = new StringBuilder(); //创建10个线程 for (int i = 0; i < 10; i++) { new Thread(new Runnable() { @Override public void run() { //每个线程循环1000次 for (int j = 0; j < 1000; j++) { sb.append("a"); } } }).start(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } //按道理10*1000=10000 System.out.println("长度本来应该是10000的,现在是:"+sb.length()); }输出
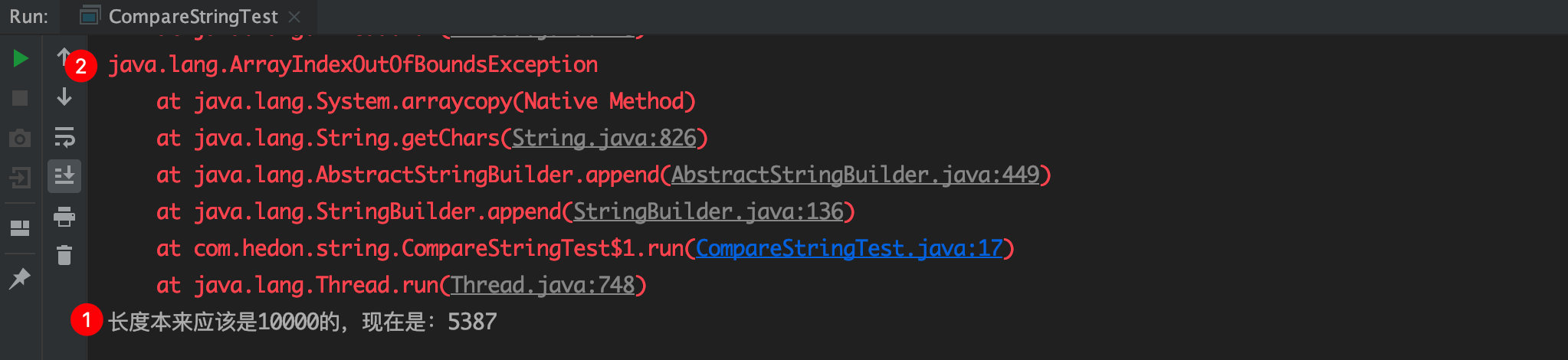
# 问题1:为什么长度才 5387?
我们先来看 StringBuilder 的 append() 方法的源码:
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
}
显然它调用了父类的 append() 方法,我们再来看看其父类的 append() 方法:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
它在扩容的时候,没有引入 synchronized 关键字,并且执行了一条非常危险的语句 count += len,这条一句实际上是 count=count+len,它不是原子性的。**所以当多个线程恰好同时执行该语句的话,那就会导致“实际 + 的次数少于应该 + 的次数”,**从而导致最后的 length < 10000。
# 问题2:为什么会报 ArrayIndexOutOfBoundsException?
这是一个数组越界的问题,所以出现问题一定是在某次读取字符数组的时候,出现了问题。所以它会在哪里读字符数组呢?这里有一条语句 str.getChars(0, len, value, count),我们来查查 JDK 文档看看对这个方法的说明:

也就是说这个方法会对 value 从 value[count] 开始插入 len 个来自 str 的字符,这里的 count 是指 StringBuilder 中有效的字符数。那么问题就来了,如果在插入 len 个字符的时候,超过 value[] 的容量呢? 比如 value 的长度为10,然后我们从 value[6] 开始插入数据,但是 len =10,那么在插入后面的数据肯定会发生数据越界问题,比如我们企图插入 value[12],就发生了越界!
回到 append() 方法,这是一个拼接字符串的方法,那么就涉及到 StringBuilder 的扩容问题了。append() 方法中的 ensureCapacityInternal(count + len) 语句就是扩容语句,我们再来看看 ensureCapacityInternal() 方法:
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
它会先尝试看看原来的 value[] 能否放下新的字符串,如果放得下就轻松了,放不下的话就调用了 newCapacity() 方法进行扩容:
private int newCapacity(int minCapacity) {
// overflow-conscious code
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
扩容的时候将 value 的长度乘以2并加上2,然后再将变成后的 value[] 复制给原 value[],这里的 value[] 和 count 都是全局变量。

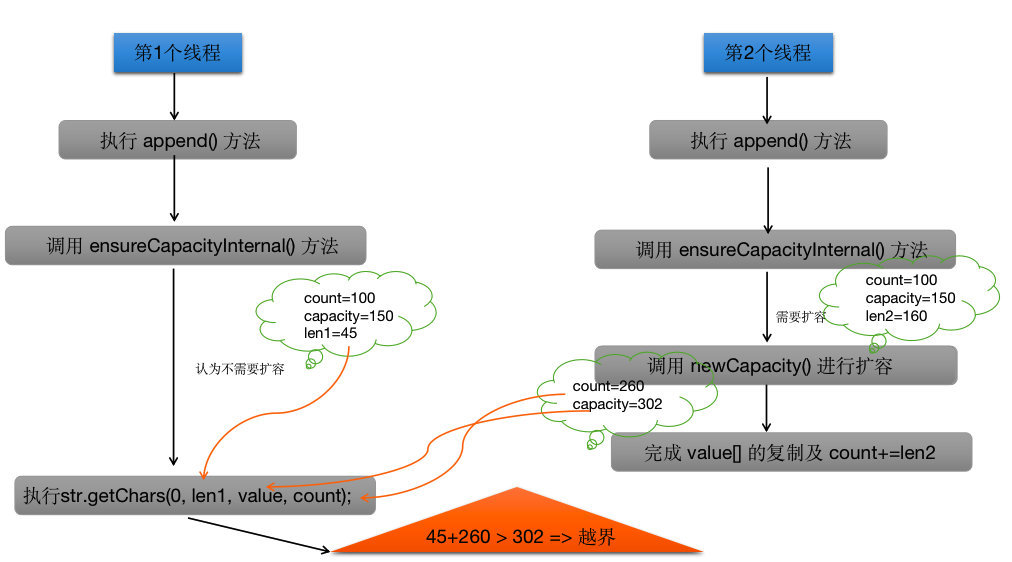
那么问题就来了,假如现在有2个线程同时执行了 append() 方法中的 ensureCapacityInternal(count + len) 语句,第1个线程不需要扩容的(假设 count=100,capacity=150,len1=45),所以它准备继续执行 str.getChars(0, len, value, count) 方法。这个时候第2个线程也来执行 ensureCapacityInternal(count + len) 语句(这个时候count=100,capacity=150,len2=160),并且它认为需要扩容,然后调用了 newCapacity()方法进行扩容使得 capacity 变成了 150*2+2 = 302 ,然后第2个线程完成了 count += len,使得 count = 260。==关键来了!==这个时候(count=260,capacity=302,len1=45)第1个线程要执行 str.getChars(0, len, value, count) 方法,这个时候就出问题了,value[] 的容量只是302,而这个时候count已经变成260了,我们需要插入45个长度的字符,所以这个时候 302<260+50,也就是说我们会访问到 value[302](数组从0开始),这就发生了越界啦!
此处如有错误(基于 JDK8.0),请批评指出!
# StringBuffer
测试 StringBuffer
public static void main(String[] args) { StringBuffer sb = new StringBuffer(); //生成10个线程 for (int i = 0; i < 10; i++) { new Thread(new Runnable() { @Override public void run() { //每个线程执行1000次 for (int j = 0; j < 1000; j++) { sb.append("a"); } } }).start(); } //让上面执行完 try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } //按道理应该 10*1000=10000 System.out.println("本来长度应该是10000,现在是:"+sb.length()); }结果

没有一点问题,我们来看看 StringBuffer 的扩容机制:
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
可以看出 SpringBuffer 的 append() 方法加了 synchronized 锁,保证的线程的安全(这也是 StringBuffer 效率比 StringBuilder 要低的原因)。
# 3. 下列程序运行结果
@Test
public void testStringBuffer(){
String str = null;
StringBuffer sb = new StringBuffer();
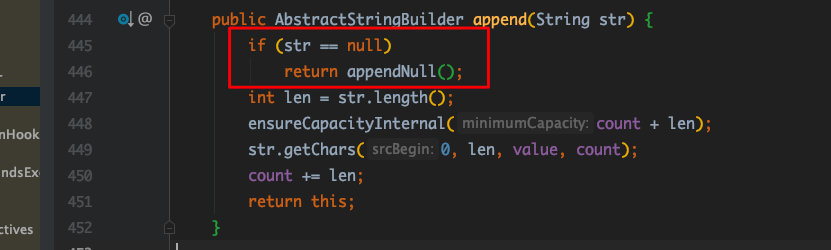
sb.append(str);
System.out.println(sb.length()); //4
System.out.println(sb); //"null"
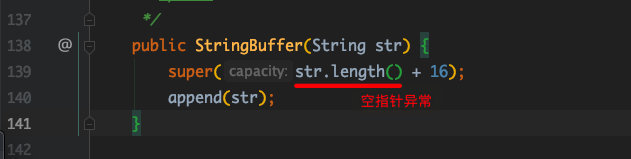
StringBuffer sb1 = new StringBuffer(str);
System.out.println(sb1); //空指针异常
}
看 append() 源码:
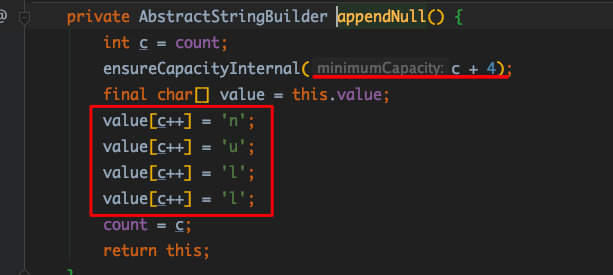
看 StringBuffer(String str) 源码: