
# 面试题丨传输层
# 1. 三次握手四次挥手
- 三次握手四次挥手过程
- 为什么要三次握手
- 为什么要四次挥手
- 四次挥手为什么有 TIME-WAIT 状态?
- 服务器出现大量 CLOSE-WAIT 状态的原因?
# 2. TCP 如何做到可靠传输
1、应用数据被分割成TCP认为最适合发送的数据块。
2、超时重传:当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
3、TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
4、校验和:TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
5、TCP 的接收端会丢弃重复的数据。
6、流量控制:TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的我数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议。
7、拥塞控制:当网络拥塞时,减少数据的发送。
# 3. TCP 的滑动窗口讲一下
# TCP 的滑动窗口
# RTT
RTT(Round-Trip Time,循环时间):发送一个数据报到收到对应 ACK 所花费的时间。
# RTO
RTO(Retransmission TimeOut:超时重传时间):重传时间间隔。
# 简介
TCP 使用滑动窗口做流量控制与乱序重排
- 保证 TCP 的可靠性
- 保证 TCP 的流控特性
# 以字节为单位滑动窗口

# TCP 缓存与滑动窗口
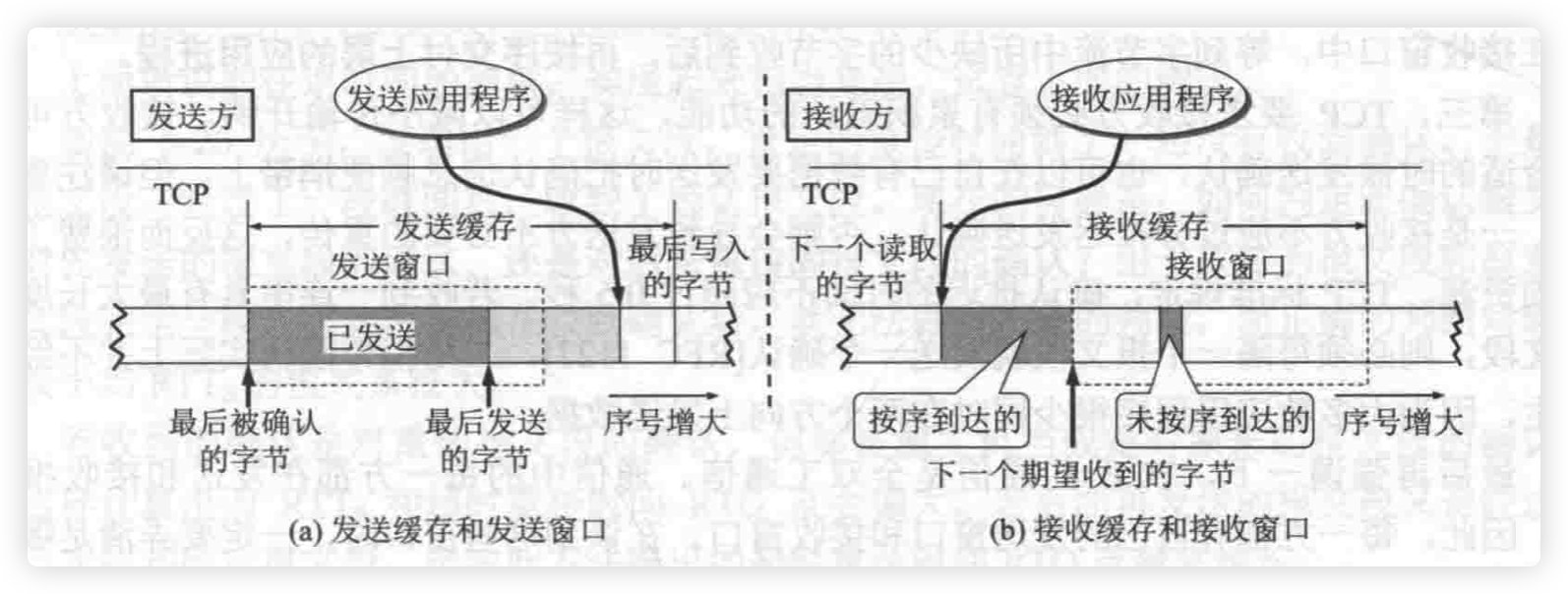
发送缓存
- 准备发送的数据
- 发送但未收到确认的数据
接收数据
- 按序到达的、但尚未被接收程序读取的数据
- 未按序到达的数据
# 4. 流量控制和拥塞控制的作用
流量控制
- 所谓流量控制就是让发送方的发送速率不要太快,让接收方来得及接收。如果接收方来不及接收发送方发送的数据,那么就会有分组丢失。在 TCP 中利用可边长的滑动窗口机制可以很方便的在 TCP 连接上实现对发送方的流量控制。主要的方式是接收方返回的 ACK 中会包含自己的接收窗口大小,以控制发送方此次发送的数据量大小(发送窗口大小)。
拥塞控制
- 在实际的网络通信系统中,除了发送方和接收方外,还有路由器,交换机等复杂的网络传输线路,此时就需要拥塞控制。拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况。常用的解决方法有:慢开始和拥塞避免、快重传和快恢复。
拥塞控制和流量控制的区别
- 拥塞控制往往是一种全局的,防止过多的数据注入到网络之中,而TCP连接的端点只要不能收到对方的确认信息,猜想在网络中发生了拥塞,但并不知道发生在何处,因此,流量控制往往指点对点通信量的控制,是端到端的问题。
# 5. 拥塞控制的手段
# 慢开始
当发送方开始发送数据时,由于一开始不知道网络负荷情况,如果立即将大量的数据字节传输到网络中,那么就有可能引起网络拥塞。一个较好的方法是在一开始发送少量的数据先探测一下网络状况,即由小到大的增大发送窗口(拥塞窗口 cwnd)。慢开始的慢指的是初始时令 cwnd为 1,即一开始发送一个报文段。如果收到确认,则 cwnd = 2,之后每收到一个确认报文,就令 cwnd = cwnd* 2。
但是,为了防止拥塞窗口增长过大而引起网络拥塞,另外设置了一个慢开始门限 ssthresh。
① 当 cwnd < ssthresh 时,使用上述的慢开始算法;
② 当 cwnd > ssthresh 时,停止使用慢开始,转而使用拥塞避免算法;
③ 当 cwnd == ssthresh 时,两者均可。
# 拥塞避免
拥塞控制是为了让拥塞窗口 cwnd 缓慢地增大,即每经过一个往返时间 RTT (往返时间定义为发送方发送数据到收到确认报文所经历的时间)就把发送方的 cwnd 值加 1,通过让 cwnd 线性增长,防止很快就遇到网络拥塞状态。
当网络拥塞发生时,让新的慢开始门限值变为发生拥塞时候的值的一半,并将拥塞窗口置为 1 ,然后再次重复两种算法(慢开始和拥塞避免),这时一瞬间会将网络中的数据量大量降低。
# 快重传
快重传算法要求接收方每收到一个失序的报文就立即发送重复确认,而不要等到自己发送数据时才捎带进行确认,假定发送方发送了 Msg 1 ~ Msg 4 这 4 个报文,已知接收方收到了 Msg 1,Msg 3 和 Msg 4 报文,此时因为接收到收到了失序的数据包,按照快重传的约定,接收方应立即向发送方发送 Msg 1 的重复确认。 于是在接收方收到 Msg 4 报文的时候,向发送方发送的仍然是 Msg 1 的重复确认。这样,发送方就收到了 3 次 Msg 1 的重复确认,于是立即重传对方未收到的 Msg 报文。由于发送方尽早重传未被确认的报文段,因此,快重传算法可以提高网络的吞吐量。
# 快恢复
快恢复算法是和快重传算法配合使用的,该算法主要有以下两个要点:
① 当发送方连续收到三个重复确认,执行乘法减小,慢开始门限 ssthresh 值减半;
② 由于发送方可能认为网络现在没有拥塞,因此与慢开始不同,把 cwnd 值设置为 ssthresh 减半之后的值,然后执行拥塞避免算法,线性增大 cwnd。
# 6. TCP 的粘包问题
半包 指接受方没有接受到一个完整的包,只接受了部分,这种情况主要是由于TCP为提高传输效率,将一个包分配的足够大,导致接受方并不能一次接受完。(在长连接和短连接中都会出现)。
粘包 指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。出现粘包现象的原因是多方面的,它既可能由发送方造成,也可能由接收方造成。发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一包数据。若连续几次发送的数据都很少,通常TCP会根据优化算法把这些数据合成一包后一次发送出去,这样接收方就收到了粘包数据。接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象。这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据。
半包影响
无法接受到完整的数据包。
粘包影响
无法区分不同的数据包。
半包解决
- 封包,加入数据长度这个变量。
粘包解决
(1)对于发送方引起的粘包现象,用户可通过编程设置来避免,TCP提供了强制数据立即传送的操作指令push,TCP软件收到该操作指令后,就立即将本段数据发送出去,而不必等待发送缓冲区满;
(2)对于接收方引起的粘包,则可通过优化程序设计、精简接收进程工作量、提高接收进程优先级等措施,使其及时接收数据,从而尽量避免出现粘包现象;
(3)由接收方控制,将一包数据按结构字段,人为控制分多次接收,然后合并,通过这种手段来避免粘包。
# 7. UDP 有粘包问题吗?
不会。
UDP 是基于报文的,每一份数据都是一个报文,都有明显的边界可以区分。
# 8. 有大量 TIME_WAIT 状态怎么办
如发现系统存在大量TIME_WAIT状态的连接,通过调整内核参数解决:编辑文件/etc/sysctl.conf
一方面我们可以调小 tw_buckets 的容量;
另一方面我们可以缩短超时时间,比如 Linux 默认 60s,我们可以缩短到 30s。
也可以尝试回收 tcp_tw_recycle:
当多个客户端通过NAT方式联网并与服务端交互时,服务端看到的是同一个IP,也就是说对服务端而言这些客户端实际上等同于一个,可惜由于这些客户端的时间戳可能存在差异,于是乎从服务端的视角看,便可能出现时间戳错乱的现象,进而直接导致时间戳小的数据包被丢弃。
也可以尝试复用:tcp_tw_reuse
顾名思义就是复用TIME_WAIT连接。当创建新连接的时候,如果可能的话会考虑复用相应的TIME_WAIT连接。通常认为「tcp_tw_reuse」比「tcp_tw_recycle」安全一些,这是因为一来TIME_WAIT创建时间必须超过一秒才可能会被复用;二来只有连接的时间戳是递增的时候才会被复用。
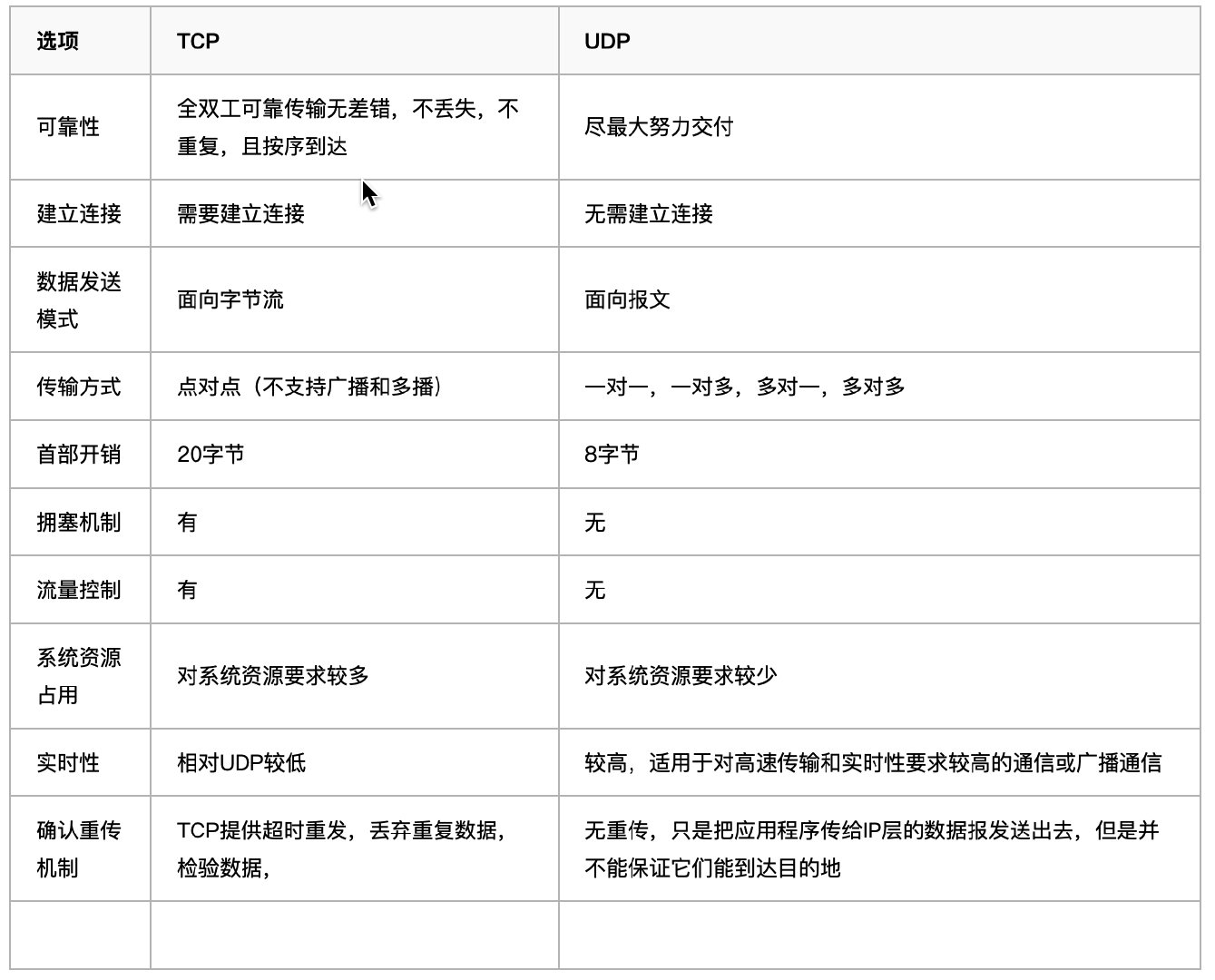
# 9. TCP 与 UDP 的比较
# 10. UDP 最大传输长度
UDP允许传输的最大长度理论上2^16 - udp head - iphead( 65507 字节 = 65535 - 20 - 8)
但是实际上UDP数据报的数据区最大长度为1472(1500-20-8)字节,理由如下:
首先,我们知道,TCP/IP通常被认为是一个四层协议系统,包括链路层,网络层,运输层,应用层.
UDP属于运输层,下面我们由下至上一步一步来看:
以太网(Ethernet)数据帧的长度必须在46-1500字节之间,这是由以太网的物理特性决定的。这个1500字节被称为链路层的MTU(最大传输单元)。 但这并不是指链路层的长度被限制在1500字节,其实这这个MTU指的是链路层的数据区。 并不包括链路层的首部和尾部的18个字节。 所以,事实上,这个1500字节就是网络层IP数据报的长度限制。 因为IP数据报的首部为20字节,所以IP数据报的数据区长度最大为1480字节.
而这个1480字节就是用来放TCP传来的TCP报文段或UDP传来的UDP数据报的。 又因为UDP数据报的首部8字节,所以UDP数据报的数据区最大长度为1472字节。这个1472字节就是我们可以使用的字节数。进行Internet编程时则不同,因为Internet上的路由器可能会将MTU设为不同的值.
如果我们假定MTU为1500来发送数据的,而途经的某个网络的MTU值小于1500字节,那么系统将会使用一系列的机制来调整MTU值,使数据报能够顺利到达目的地,这样就会做许多不必要的操作。鉴于Internet上的标准MTU值为576字节, 建议在进行Internet的UDP编程时. 最好将UDP的数据长度控件在548字节(576-8-20)以内.
# 11. TCP 确认重传机制
在发送一个数据之后,就开启一个定时器,若是在这个时间内没有收到发送数据的ACK确认报文,则对该报文进行重传,在达到一定次数还没有成功时放弃并发送一个复位信号。
# 12. 四次挥手为什么需要 2MSL?
- 保证服务端有时间可以收到客户端最后发送的 ACK 包。
- 防止新旧连接混淆。因为如果没有 2MSL 的话,如果有一个报文之前超时了还没传好,然后新的连接又刚好 ip 和 port 都等于之前这个连接的话,那它就会出现在这次的新连接当中,就造成了新旧连接混淆。
# 13. TCP 连接队列讲一下
使用 socket 的时候,当服务端调用 listen 函数监听端口的时候,内核会为每个监听的socket创建两个队列:
- 半连接队列(syn queue):客户端发送
SYN包,服务端收到后回复SYN+ACK后,服务端进入SYN_RCVD状态,这个时候的socket会放到半连接队列。(第二次握手后) - 全连接队列(accept queue):当服务端收到客户端的ACK后,socket会从半连接队列移出到全连接队列。当调用 accpet 函数的时候,会从全连接队列的头部返回可用socket给用户进程。(三次握手完成后)
# 14. SYNflood 以及解决方法
SYNFlood 就是 B 发送给 A 的 SYN-ACK 包没有得到回应,然后 B 就一直进行超时重传。然后 A 一直不反馈 B 的 SYN-ACK 包,一直持续不断的发送 SYN 包,导致资源耗尽。
思路一:B 回给 SYN-ACK 后进入一种半连接的状态,我们可以提高这个半连接状态的容量
思路二:控制重传的次数,不然它无休止地耗费资源。
SYC Cache
SYN Cache的出发点主要是针对“鸠占鹊巢”问题,基本原理如下:构造一个全局的Hash Table (opens new window),用来缓存系统当前所有的半开连接信息,连接成功则从Cache中清除相关信息;Hash Table中每个桶(bucket)的容量大小也有限制,当桶“满”时做除旧迎新操作。当B收到一个SYN消息后,会将半开连接信息加入到Hash Table中,其中key的生成很关键,既要用到SYN消息中包含的信息(如:Source IP,Port等)又要做到很难被攻击者猜到,一般会通过一个秘密的函数生成,这样所有的半开连接无论好坏,都看似随机地被平均分配到了不同的“桶”中,使攻击难度大增,因为为达到DoS效果,攻击者需要使每个桶都达到填满状态,并且还要有足够快的“填桶”速度,使得正常的半开连接在还未完成建立前就被踢出桶,这样的攻击行为估计在达到目的前早就暴露了。
SYN Cookie
SYN Cookies (opens new window)着眼点主要是设法消除半开连接的资源消耗,原理与HTTP Cookies技术类似,B通过特定的算法把半开连接信息编码成“Cookie”,用作B给A的消息编号(SequenceNum),随SYN-ACK消息一同返回给连接发起方A,这样在连接完全建立前B不保存任何信息。如果A是正常用户,则会向B发送最后一次握手消息(ACK),B收到后验证“Cookie”的内容并建立连接;如果A是攻击者,则不会向B反馈ACK消息,B也没任何损失,也就说是单纯的SYN攻击不会造成B的连接资源消耗。当然这种方案也有一定缺点,最明显的就是B不保存连接的半开状态,就丧失了重发SYN-ACK消息的能力,这一方面会降低正常用户的连接成功率,另一方面会导致某些情况下正常通信的双方会对连接是否成功打开产生误解,如A发给B的第三次握手消息(ACK)半路遗失,A认为连接成功了,B认为没收到ACK,连接没成功,这种情况就需要上层应用采取策略特别处理了。