
# Kubernetes 集群搭建
# 1. 环境规划
# 1.1 集群类型
Kubernetes集群大致分为两类:一主多从和多主多从。
一主多从:一个 Master 节点和多台 Node 节点,搭建简单,但是有单机故障风险,适合用于测试环境。
多主多从:多台 Master 和多台 Node 节点,搭建麻烦,安全性高,适合用于生产环境。
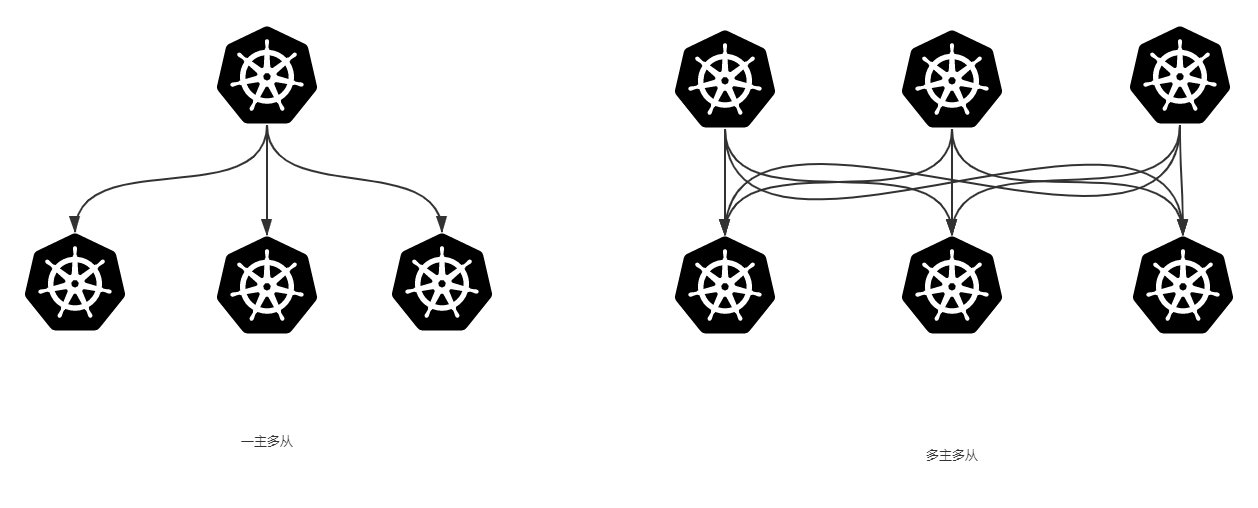
本文使用一主多从。
# 1.2 安装方式
Kubernetes 有多种部署方式,目前主流的方式有 Kubeadm、minikube、二进制包:
- Kubeadm:一个用于快速搭建 kubernetes 集群的工具。
- minikube:一个用于快速搭建单节点的 Kubernetes 工具。
- 二进制包:从官网上下载每个组件的二进制包,依次去安装,此方式对于理解 Kubernetes 组件更加有效。
# 1.3 主机规划
| 角色 | IP地址 | 操作系统 | 配置 |
|---|---|---|---|
| Master | 172.16.58.200 | CentOS7.9,基础设施服务器 | 2核CPU,2G内存,50G硬盘 |
| Node1 | 172.16.58.201 | CentOS7.9,基础设施服务器 | 2核CPU,2G内存,50G硬盘 |
| Node2 | 172.16.58.202 | CentOS7.9,基础设施服务器 | 2核CPU,2G内存,50G硬盘 |
Mac 上如何配置虚拟机静态 IP 可以参考:Mac 上 VMware 配置 CentOS 静态IP
# 2. 环境规划
# 2.1 前言
- 本次环境搭建需要三台CentOS服务器(一主二从),然后在每台服务器中分别安装Docker(18.06.3)、kubeadm(1.18.0)、kubectl(1.18.0)和kubelet(1.18.0)。
没有特殊说明,就是三台机器都需要执行。
# 2.2 环境初始化
# 2.2.1 检查操作系统版本
检查操作系统的版本(要求操作系统的版本至少在7.5以上):
$ cat /etc/redhat-release # 输出 CentOS Linux release 7.9.2009 (Core)
# 2.2.2 关闭防火墙和禁止防火墙开机启动
关闭防火墙
$ systemctl stop firewalld禁止防火墙开机启动
$ systemctl disable firewalld # 输出 Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
# 2.2.3 设置主机名
hostnamectl set-hostname <hostname>
设置 172.16.58.200 主机名
hostnamectl set-hostname k8s-master设置 172.16.58.201 主机名
hostnamectl set-hostname k8s-node1设置 172.16.58.202 主机名
hostnamectl set-hostname k8s-node2
# 2.2.4 主机名解析
为了方便后面集群节点间的直接调用,需要配置一下主机名解析,企业中推荐使用内部的DNS服务器。
cat >> /etc/hosts << EOF 172.16.58.200 k8s-master 172.16.58.201 k8s-node1 172.16.58.202 k8s-node2 EOF
# 2.2.5 时间同步
Kubernetes 要求集群中的节点时间必须精确一致,所以在每个节点上添加时间同步:
安装网络时间同步器
yum install ntpdate -y同步时间
ntpdate time.windows.com
# 2.2.6 关闭 selinux
查看 selinux 是否开启
$ getenforce Enforcing永久关闭 selinux,需要重启:
sed -i 's/enforcing/disabled/' /etc/selinux/config临时关闭 selinux,重启之后无效:
setenforce 0
# 2.2.7 关闭 swap 分区
swap 分区指的是虚拟内存分区,它的作用是在物理内存使用完之后,将磁盘空间虚拟成内存来使用。
启用 swap 设备会对系统的性能产生非常负面的影响,因此 Kubernetes 要求每 个节点都要禁用 swap 设备
但是如果因为某些原因确实不能关闭 swap 分区,就需要在集群安装过程中通过明确的参数进行配置说明。
永久关闭 swap 分区,需要重启:
sed -ri 's/.*swap.*/#&/' /etc/fstab咱是关闭 swap 分区,重启之后无效:
swapoff -a
# 2.2.8 将桥接的 IPv4 流量传递到 iptables 的链
在每个节点上将桥接的IPv4流量传递到iptables的链:
cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 vm.swappiness = 0 EOF加载网桥过滤模块
br_netfilter模块:modprobe br_netfilter查看网络过滤模块是否加载:
$ lsmod | grep br_netfilter # 输出 br_netfilter 22256 0 #这个就是网桥过滤模块 bridge 151336 1 br_netfilter生效:
$ sysctl --system # 输出 * Applying /usr/lib/sysctl.d/00-system.conf ... ..... * Applying /etc/sysctl.conf ...
# 2.2.9 开启 ipvs
在 Kubernetes 中 Service 有两种代理模型,一种是基于 iptables,另一种是基于 ipvs 的。ipvs 的性能要高于 iptables 的,但是如果要使用它,需要手动载入ipvs模块。
在每个节点安装
ipset和ipvsadm:yum -y install ipset ipvsadm在所有节点执行如下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF为脚本添加执行权限:
chmod 755 /etc/sysconfig/modules/ipvs.modules执行脚本:
bash /etc/sysconfig/modules/ipvs.modules查看是否
ipvs载入成功:$ lsmod | grep -e ip_vs -e nf_conntrack_ipv4 # 输出 ip_vs_sh 12688 0 ip_vs_wrr 12697 0 ip_vs_rr 12600 0 ip_vs 145458 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr nf_conntrack_ipv4 15053 2 nf_defrag_ipv4 12729 1 nf_conntrack_ipv4 nf_conntrack 139264 6 ip_vs,nf_nat,nf_nat_ipv4,xt_conntrack,nf_nat_masquerade_ipv4,nf_conntrack_ipv4 libcrc32c 12644 4 xfs,ip_vs,nf_nat,nf_conntrack
# 2.2.10 重启三台机器
reboot
检查 selinux 是否关闭:
$ getenforce检查 swap 分区是否关闭:
$ free -m
# 2.3 每个节点安装 Docker、kubeadm、kubelet 和 kubectl
# 2.3.1 安装 Docker
安装 Docker:
切换镜像源:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo安装 Docker:
yum -y install docker-ce-18.06.3.ce-3.el7启动 Docker:
systemctl start docker设置 Docker 开机自启动:
systemctl enable docker &&检查 Docker 版本,确保安装成功:
docker version
设置 Docker 镜像加速器:
找到镜像加速器配置方式:

配置镜像加速器
sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://upv8c0bn.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart dockerDocker 在默认情况下使用
Cgroup Driver为cgroupfs,而 Kubernetes 推荐使用systemd来替代cgroupfs,所以我们需要再次修改上面的/etc/docker/daemon.json文件,修改后内容为:{ "exec-opts": ["native.cgroupdriver=systemd"], "registry-mirrors": ["https://upv8c0bn.mirror.aliyuncs.com"] }
# 2.3.2 添加阿里云的 YUM 软件源
由于 Kubernetes 的镜像源在国外,非常慢,这里切换成国内的阿里云镜像源:
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 2.3.3 安装 kubeadm、kubelet 和 kubectl
由于版本更新频繁,这里指定版本号部署:
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0为了实现 Docker 使用的
cgroup drvier和kubelet使用的cgroup drver一致,建议修改"/etc/sysconfig/kubelet"文件的内容:vim /etc/sysconfig/kubelet修改:
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd" KUBE_PROXY_MODE="ipvs"
设置为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动:
systemctl enable kubelet
# 2.4 准备 k8s 集群所需镜像
查看集群所需镜像:
kubeadm config images list
输出:
k8s.gcr.io/kube-apiserver:v1.18.20
k8s.gcr.io/kube-controller-manager:v1.18.20
k8s.gcr.io/kube-scheduler:v1.18.20
k8s.gcr.io/kube-proxy:v1.18.20
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.7
由于后面在初始化 k8s 集群的时候需要运行 kubeadm init,它会从 k8s 官方拉取上述镜像,由于国内网络原因很困难导致拉取失败,所以这里我们先从阿里云提前拉取镜像:
images=(
kube-apiserver:v1.18.20
kube-controller-manager:v1.18.20
kube-scheduler:v1.18.20
kube-proxy:v1.18.20
pause:3.2
etcd:3.4.3-0
coredns:1.6.7
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
done
查看镜像:
docker images
输出:
[root@k8s-master ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-proxy v1.18.20 27f8b8d51985 2 weeks ago 117MB
k8s.gcr.io/kube-apiserver v1.18.20 7d8d2960de69 2 weeks ago 173MB
k8s.gcr.io/kube-scheduler v1.18.20 a05a1a79adaa 2 weeks ago 96.1MB
k8s.gcr.io/kube-controller-manager v1.18.20 e7c545a60706 2 weeks ago 162MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 16 months ago 683kB
k8s.gcr.io/coredns 1.6.7 67da37a9a360 17 months ago 43.8MB
k8s.gcr.io/etcd 3.4.3-0 303ce5db0e90 20 months ago 288MB
# 3. 初始化集群
集群初始化的时候只需在
Master节点上进行初始化,然后再将Node节点加入到 Master 节点即可。
# 3.1 初始化 Master 节点
只在 Master节点(172.16.58.200)上执行。
创建集群:
[root@k8s-master ~]# kubeadm init \ --kubernetes-version v1.18.20 \ --service-cidr=10.96.0.0/12 \ --pod-network-cidr=10.244.0.0/16 \ --apiserver-advertise-address=172.16.58.200- kubernetes-version:k8s 版本,注意要跟前面安装的镜像对齐
- pod-network-cidr:Pod 节点网络,跟我保持一致即可
- service-cidr:Service 网络,跟我保持一致即可
- apiserver-advertise-address:改成
Master 节点的 IP 地址
上述执行后输出:
# 安装成功 Your Kubernetes control-plane has initialized successfully! # 后续需要创建的文件 To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config # 部署网络需要执行的操作 You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ # Node 节点要加入的时候需要执行的东西 Then you can join any number of worker nodes by running the following on each as root: kubeadm join 172.16.58.200:6443 --token ew64tz.d4ju2wovg684bz6u \ --discovery-token-ca-cert-hash sha256:e4959de30bb94df662147bdf32044d5278eecd7c77f2e56b51ae07860a52fd79根据提示创建必要文件:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 3.2 Node 加入到 Master 节点中
Node1 加入:
[root@k8s-node1 ~]# kubeadm join 172.16.58.200:6443 --token ew64tz.d4ju2wovg684bz6u \ > --discovery-token-ca-cert-hash sha256:e4959de30bb94df662147bdf32044d5278eecd7c77f2e56b51ae07860a52fd79 W0701 20:33:10.083754 9549 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set. [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... # 成功加入 This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. # 在 Master 节点可以执行该命名查看 Node 是否已经加入集群 Run 'kubectl get nodes' on the control-plane to see this node join the cluster.Node2 加入:
kubeadm join 172.16.58.200:6443 --token ew64tz.d4ju2wovg684bz6u \ --discovery-token-ca-cert-hash sha256:e4959de30bb94df662147bdf32044d5278eecd7c77f2e56b51ae07860a52fd79Master 检查 Node 加入情况:
[root@k8s-master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master NotReady master 5m27s v1.18.0 k8s-node1 NotReady <none> 95s v1.18.0 k8s-node2 NotReady <none> 7s v1.18.0可以看到
Node1和Node2都已经加入到集群当中了,但是Status还是NotReady的状况,各个节点之前还无法互相通信,这是因为我们还没安装 CNI 网络插件。
# 3.3 Node 永久加入到 Master 节点
上述 Node 加入到 Master 节点的 token 有效期只有 24 小时,当过期之后,token 就不能用了,我们可以通过以下方式创建一个新的 token:
kubeadm token create --print-join-command
也可以创建永久 token:
kubeadm token create --ttl 0 --print-join-command
等刚刚使用的 token 过期后,再在 Node 节点执行输出的内容就可以永久加入到 Master 节点了。
# 4. 安装 CNI 网络插件
Kubernetes 支持多种网络插件,比如 flannel、calico、canal 等,任选一种即可,本次选择 flannel。
下面操作只需要在
Master节点执行即可,插件使用的是DaemonSet的控制器,它会在每个节点上运行。
获取
fannel配置文件wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml使用配置文件启动
flannel[root@k8s-master ~]# kubectl apply -f kube-flannel.yml podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created稍等片刻,再次查看集群节点状态
[root@k8s-master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master Ready master 18m v1.18.0 k8s-node1 Ready <none> 15m v1.18.0 k8s-node2 Ready <none> 13m v1.18.0查看集群监控状况:
[root@k8s-master ~]# kubectl get cs NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy {"health":"true"}查看集群信息
[root@k8s-master ~]# kubectl cluster-info Kubernetes master is running at https://172.16.58.200:6443 KubeDNS is running at https://172.16.58.200:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
# 5. 服务部署
# 5.1 前言
前面我们已经完成了 一主二从 的 k8s 集群搭建了,下面我们来在 k8s 集群中部署一个 Nginx 程序,测试我们的集群是否能正常工作。
# 5.2 步骤
以下操作都只需要在
Master节点操作。
部署 Nginx
[root@k8s-master ~]# kubectl create deployment nginx --image=nginx:1.14-alpine deployment.apps/nginx created暴露端口
[root@k8s-master ~]# kubectl expose deployment nginx --port=80 --type=NodePort service/nginx exposedport:暴露的端口号
type:NodePort 表示允许集群以外的浏览器访问
查看服务状态
[root@k8s-master ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-55f8fd7cfc-g78sc 1/1 Running 0 96s [root@k8s-master ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24m nginx NodePort 10.96.57.51 <none> 80:30399/TCP 70s上述可以看到暴露给外界的端口号是:
30399,所以我们可以通过集群内的节点IP:30399来访问 Nginx。在宿主机访问部署的 Nginx 服务
Master:

Node1:

Node2:

🥳🥳🥳 至此,我们就把 Kubernetes 的集群给成功搭建起来啦!
🥳🥳🥳 Congratulations!!!!!