
# 13. 锁
总结
- Go 锁的两大基础
- atomic
- sema
- Mutex
- 正常模式:得到锁返回,得不到锁自旋,自旋多了就饥饿;
- 饥饿模式:不自选,直接入队等待。依次从队里唤醒协程并授予锁;
- RWMutex
- 只能一个写;
- 可以同时多个读;
- WaitGroup:一组协程等待另外一组协程全部执行完毕再执行;
- Once:控制一段代码在并发中只执行一次;
- 排除锁异常问题
- 锁拷贝 go vet
- 数据竞争问题 go build -race
- 死锁 go-deadlock
# 13.1 原子操作
# 13.1.1 atomic 包
Go 在 sync/atomic 包提供了一系列基本类型的原子操作,使用这些操作,可以保证基本类型在高并发下的并发安全性,实现原子操作。
- SwapInt32
- CompareAndSwapInt32
- AddInt32
- LoadInt32
- StoreInt32
# 13.1.2 底层
// AddInt32 atomically adds delta to *addr and returns the new value.
func AddInt32(addr *int32, delta int32) (new int32)
汇编:可以发现用了一个 LOCK
// uint32 Xadd(uint32 volatile *val, int32 delta)
// Atomically:
// *val += delta;
// return *val;
TEXT ·Xadd(SB), NOSPLIT, $0-12
MOVL ptr+0(FP), BX
MOVL delta+4(FP), AX
MOVL AX, CX
LOCK
XADDL AX, 0(BX)
ADDL CX, AX
MOVL AX, ret+8(FP)
RET
- atomic 是一种硬件层面加锁的机制;
LOCK命令保证操作一个变量的时候,其他协程 / 线程无法访问该变量;- 只能用于简单变量的简单操作;
# 13.2 sema 锁
# 13.2.1 概述
- sema 锁全称 semaphore,也叫信号锁 / 信号量锁;
- sema 的核心是一个
uint32类型的值,含义是同时可并发的协程数量; - 每一个 sema 锁都对应一个
semaRoot结构体; semaRoot中有一个平衡二叉树用于协程排队;
PS:可以阅读 Java 并发工具 —— 信号量 (opens new window) ,看看有何不同。
# 13.2.2 底层
sync/mutex.go下的Mutex结构体:type Mutex struct { state int32 sema uint32 }其中第一个元素 sema,便是一个 sema 锁,它本质上是一个
semaRoot结构体的值。runtime/sema.go下的semaRoot结构体:type semaRoot struct { lock mutex treap *sudog // root of balanced tree of unique waiters. nwait uint32 // Number of waiters. Read w/o the lock. } type mutex struct { lockRankStruct key uintptr } type sudog struct { g *g next *sudog prev *sudog elem unsafe.Pointer // data element (may point to stack) acquiretime int64 releasetime int64 ticket uint32 isSelect bool success bool parent *sudog // semaRoot binary tree waitlink *sudog // g.waiting list or semaRoot waittail *sudog // semaRoot c *hchan // channel }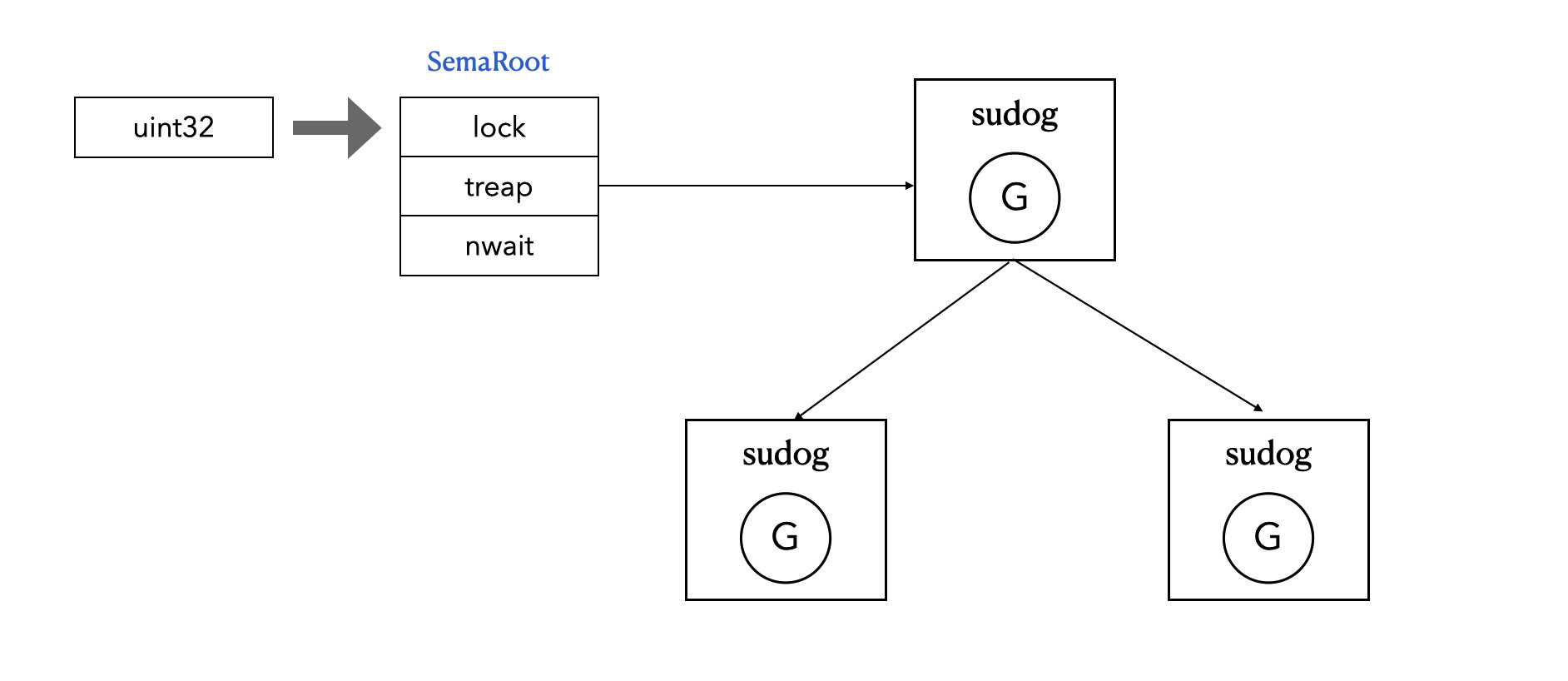
# 13.2.3 操作
当 unit32 > 0 时,表示可以并发的协程个数
- 获取锁:sema - 1, 获得锁成功
- 释放锁:sema + 1,释放锁成功
当 unit32 = 0 时,表示没锁了,sema 锁退化成一个专用的休眠队列
- 获取锁:进入堆树等待,协程休眠;
- 释放锁:从堆树中取出一个协程并唤醒
# 13.2.4 semeacquire()
- sema > 0:sema --
- sema = 0:将协程放入堆树中等待,并休眠
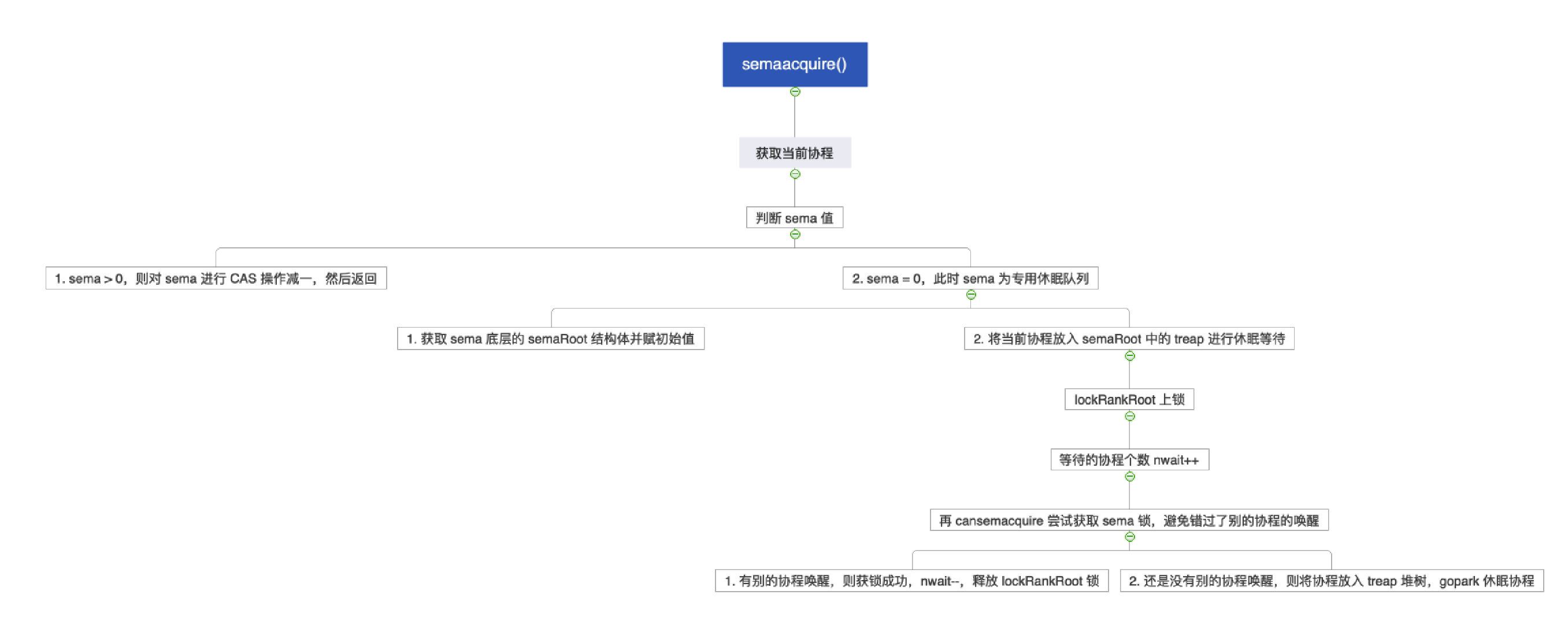
// semacquire1 请求获取 sema 锁
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {
// 1. 获取当前协程
gp := getg()
if gp != gp.m.curg {
throw("semacquire not on the G stack")
}
// 2. 操作 sema 的 uint32 值
// 2.1 如果 sema > 0,则对 sema 进行 CAS 操作减一,获得锁,返回
// 2.2 如果 sema = 0,则此时 sema 为专用休眠队列,继续往下走
if cansemacquire(addr) {
return
}
// 3. 获取 sema 底层的 semaRoot,并为它赋初始值
s := acquireSudog()
root := semroot(addr)
t0 := int64(0)
s.releasetime = 0
s.acquiretime = 0
s.ticket = 0
if profile&semaBlockProfile != 0 && blockprofilerate > 0 {
t0 = cputicks()
s.releasetime = -1
}
if profile&semaMutexProfile != 0 && mutexprofilerate > 0 {
if t0 == 0 {
t0 = cputicks()
}
s.acquiretime = t0
}
// 4. 将当前协程放入堆树中进行等待
for {
// 4.1 上锁
lockWithRank(&root.lock, lockRankRoot)
// 4.2 等待的协程个数 + 1
atomic.Xadd(&root.nwait, 1)
// 4.3 再检查一遍是否可以获得 sema 锁
// 因为这个时候可能有别的地方调用了 semarelase 唤醒了该协程
if cansemacquire(addr) {
atomic.Xadd(&root.nwait, -1)
unlock(&root.lock)
break
}
// 4.4 将协程放入堆树
root.queue(addr, s, lifo)
// 4.5 gopark 协程休眠
goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
if s.releasetime > 0 {
blockevent(s.releasetime-t0, 3+skipframes)
}
releaseSudog(s)
}
// cansemacquire 判断是否可以获得 sema 锁
func cansemacquire(addr *uint32) bool {
for {
// 1. 加载 sema 值
v := atomic.Load(addr)
// 2. sema = 0,不可
if v == 0 {
return false
}
// 3. sema > 0,做 CAS 操作减一
if atomic.Cas(addr, v, v-1) {
return true
}
}
}
# 13.2.5 semarelease()
- 无等待中的协程:直接返回
- 有等待中的协程:从堆树中出队一个协程,唤醒,并调度到当前 P 的 runq 中
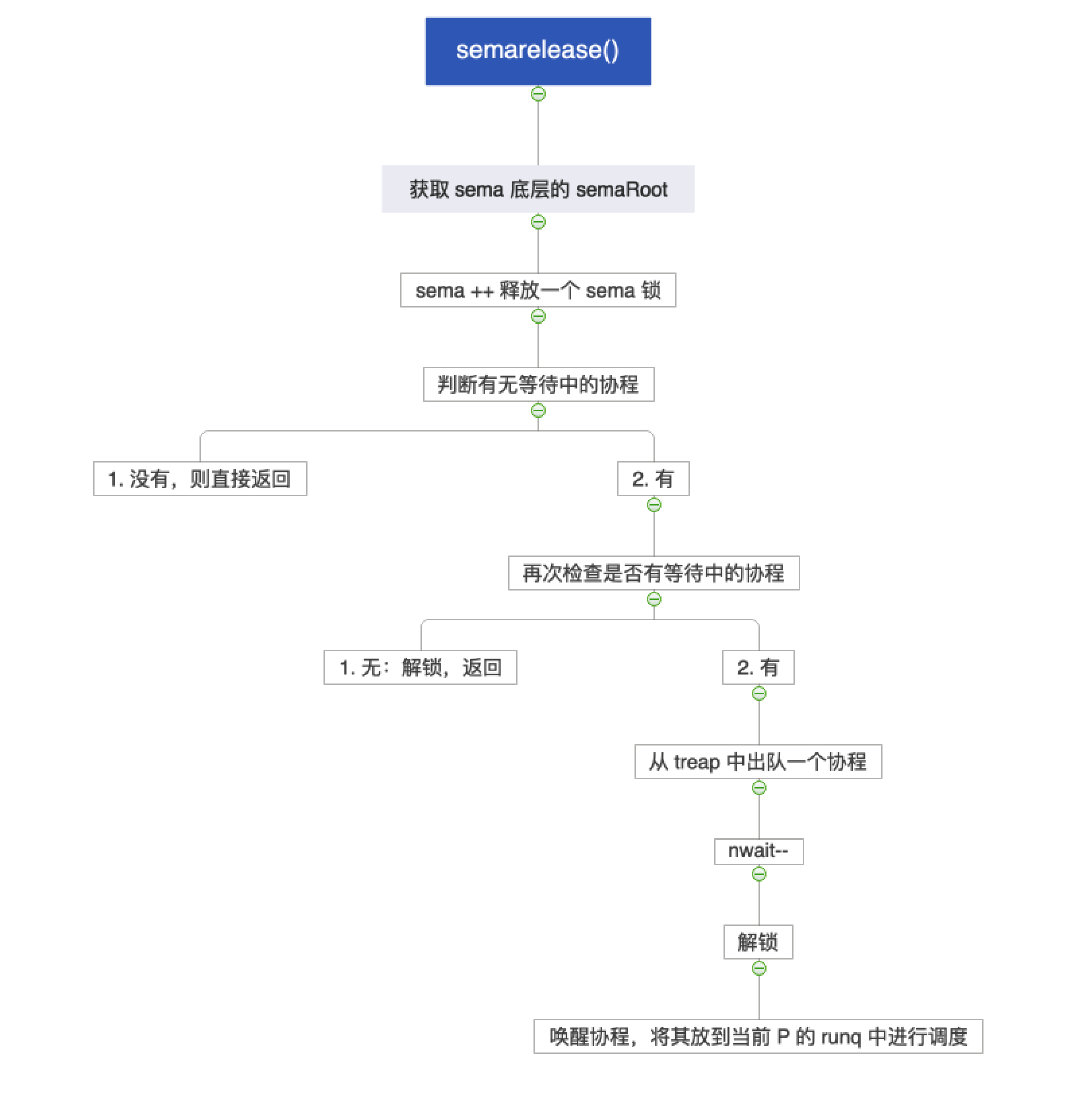
func semrelease1(addr *uint32, handoff bool, skipframes int) {
// 1. 获取 sema 底层的 semaRoot
root := semroot(addr)
// 2. sema ++
atomic.Xadd(addr, 1)
// 3. 判断有没有等待中的协程,该操作必须在 Xadd 之后
// 这是因为 sema++ 后,另一个协程在 semaacquire 的时候就可以
// 直接拿到 sema 而不用进入休眠了,就刚好有可能 nwait = 0
if atomic.Load(&root.nwait) == 0 {
return
}
// 4. 有等待中的协程,在 treap 中找到一个协程出队并唤醒它
// 4.1 上锁
lockWithRank(&root.lock, lockRankRoot)
// 4.2 再次检查,因为有可能在上面 Xadd 和 Load 之后,有的协程就已经拿到锁了
if atomic.Load(&root.nwait) == 0 {
unlock(&root.lock)
return
}
// 4.3 还是有等待中的协程,那就出队
s, t0 := root.dequeue(addr)
// 4.4 出队成功,nwait--
if s != nil {
atomic.Xadd(&root.nwait, -1)
}
// 4.4 解锁
unlock(&root.lock)
if s != nil { // May be slow or even yield, so unlock first
acquiretime := s.acquiretime
if acquiretime != 0 {
mutexevent(t0-acquiretime, 3+skipframes)
}
if s.ticket != 0 {
throw("corrupted semaphore ticket")
}
if handoff && cansemacquire(addr) {
s.ticket = 1
}
readyWithTime(s, 5+skipframes)
if s.ticket == 1 && getg().m.locks == 0 {
// 4.5 唤醒当前协程,放到当前 P 的 runq 上
goyield()
}
}
}
# 13.3 sync.Mutex
# 13.3.1 概述
sync.Mutex 是最简单的一种锁类型 —— 互斥锁,同时也比较暴力,当一个 Goroutine 获得了 Mutex 后,其他 Goroutine 就只能乖乖等到这个 Goroutine 释放该 Mutex。
每个资源都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源,其它的协程只能等待。
互斥锁是传统并发编程对共享资源进行访问控制的主要手段,它由标准库 sync 中的 Mutex 结构体类型表示。sync.Mutex 类型只有两个公开的指针方法:Lock 和 Unlock。
m.Lock:锁定当前的共享资源m.Unlock:进行解锁
# 13.3.2 底层
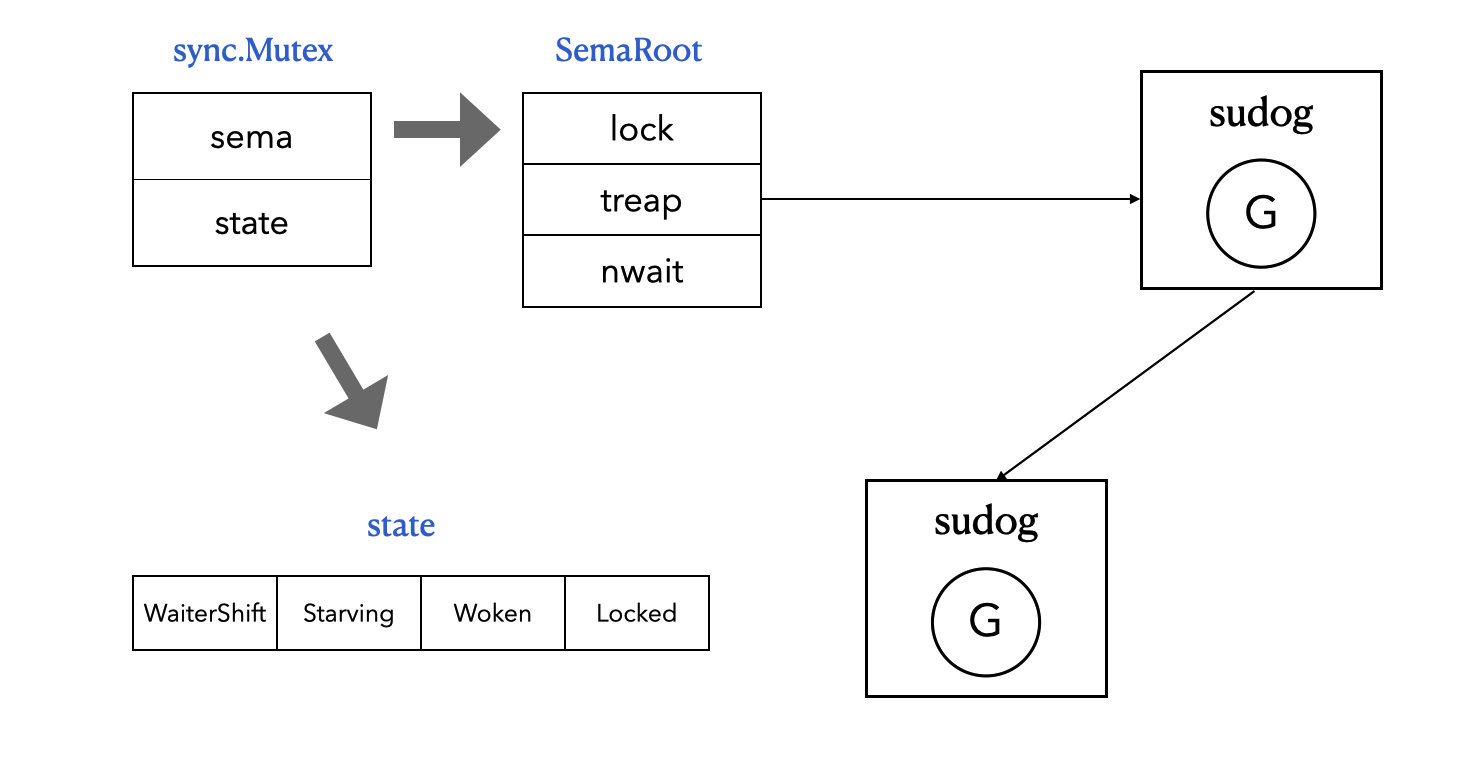
sync.Mutex
type Mutex struct {
state int32
sema uint32
}
- same 便是前面讲的 sema 锁。
- state 是一个 32 位的 int32 值,它总共由 4 个部分组成:
- 0:mutexLocked,标志当前是否被锁上了,0 表示没有锁,1 表示被锁了
- 1:mutexWoken,是否被唤醒
- 2:mutexStarving,是否是饥饿模式
- 3 - 31:mutexWaiterShift,等待该锁的协程的数量
# 13.3.3 上锁
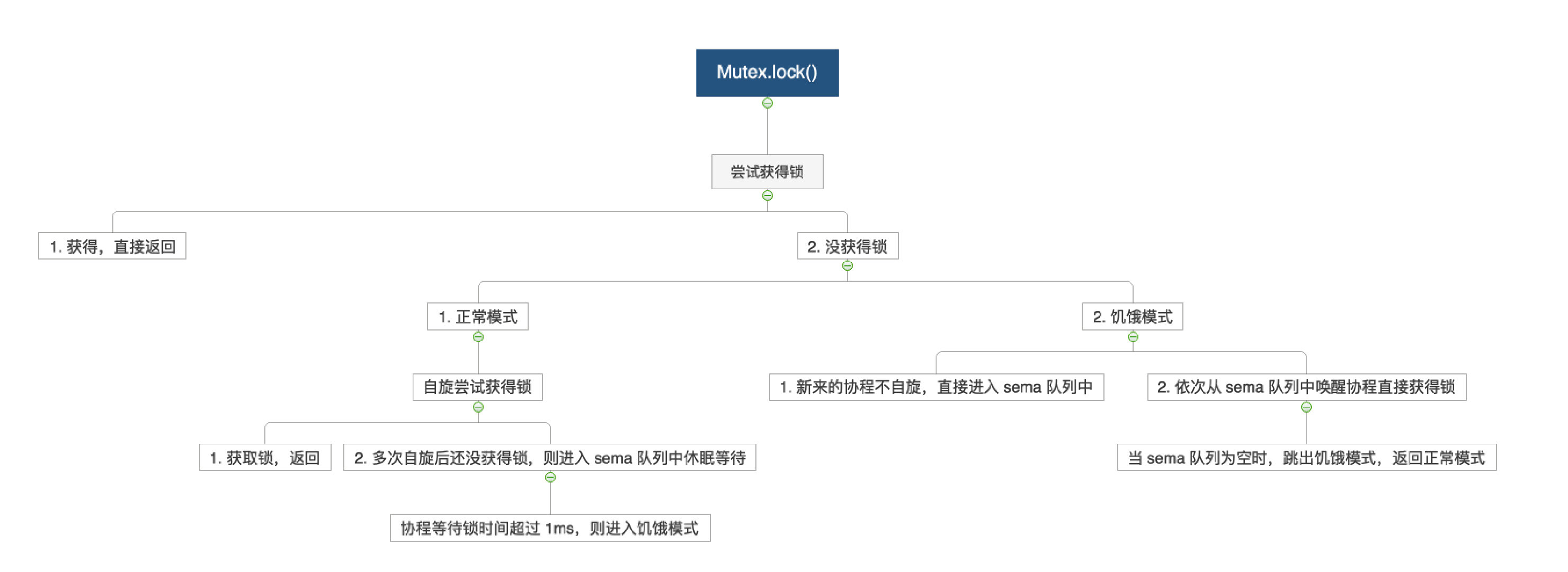
- 正常模式:获得锁直接返回,得不到锁就自旋,自旋多次后进入 sema 队列中休眠,超过 1ms 就转为饥饿模式;
- 饥饿模式:
- 新来的协程不自旋,直接今年入 sema 队列中;
- 依次从 sema 队列中唤醒协程,并直接获得锁,当 sema 队列为空时,跳回正常模式
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// 1. 尝试获得锁,也就是将 mutexLocked 用 CAS 操作将其从 0 置为 1
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
// 2. 获得锁就直接返回
return
}
// 3. 没获得锁,继续往下走
m.lockSlow()
}
func (m *Mutex) lockSlow() {
// 计时,记录当前协程在争夺锁过程中的等待时间
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
// 4. 自旋,不断尝试获得锁
for {
// 4.1 检查是否满足自旋条件
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// 4.1.2 尝试唤醒当前 gouroutine
// !awoke 判断当前 goroutine 是不是在唤醒状态
// old&mutexWoken == 0 表示没有其他正在唤醒的 goroutine
// old>>mutexWaiterShift != 0 表示等待队列中有正在等待的 goroutine
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
// 尝试将当前锁的低2位的Woken状态位设置为1,表示已被唤醒
// 这是为了通知在解锁Unlock()中不要再唤醒其他的waiter了
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
// 4.1.2 自旋
runtime_doSpin()
iter++
old = m.state
continue
}
// 4.2 不满足自旋条件
new := old
// 4.2.1 如果当前锁不是饥饿模式,则将new的低1位的Locked状态位设置为1,表示加锁
if old&mutexStarving == 0 {
new |= mutexLocked
}
// 4.2.2 如果当前锁已被加锁或者处于饥饿模式,则将 waiter 数加1,表示当前 goroutine 将被作为waiter 置于等待队列队尾
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// 4.2.3 如果当前锁处于饥饿模式,并且已被加锁,则将低3位的Starving状态位设置为1,表示饥饿
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
// 4.2.4 当 awoke 为true,则表明当前 goroutine 在自旋逻辑中,成功修改锁的 Woken 状态位为 1
if awoke {
// 4.2.5 将唤醒标志位Woken置回为0
// 因为在后续的逻辑中,当前goroutine要么是拿到锁了,要么是被挂起。
// 如果是挂起状态,那就需要等待其他释放锁的goroutine来唤醒。
// 假如其他goroutine在unlock的时候发现Woken的位置不是0,则就不会去唤醒,那该goroutine就无法再醒来加锁。
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
// 4.2.5 尝试将锁的状态更改为 new
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 状态更改成功
// 锁的原状态不是 locked 也不是 starving,说明当前 goroutine 获取锁成功,直接返回
if old&(mutexLocked|mutexStarving) == 0 {
break
}
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 自旋多次后,再次尝试获取锁无果
// 因为 Mutex 的 sema=0,所以其实这里是休眠当前 goroutine
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 别的协程解锁后,当前协程被唤醒,继续争夺锁
// 判断当前协程是否饥饿
// ① 本来就饥饿
// ② 当前 goroutine 等待锁时间 > 1ms
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
// 饥饿模式下,锁会直接交给唤醒的 goroutine
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 等待队列 --
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
// 拿到锁,退出
break
}
// 如果锁不是饥饿状态
// 因为当前goroutine已经被信号量唤醒了
// 那就将表示当前goroutine状态的awoke设置为true
// 并且将自旋次数的计数iter重置为0,如果能满足自旋条件,重新自旋等待
awoke = true
iter = 0
} else {
// 4.2.5 无法将锁的状态更改为 new,那就重来,再试试
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
# 13.3.4 解锁
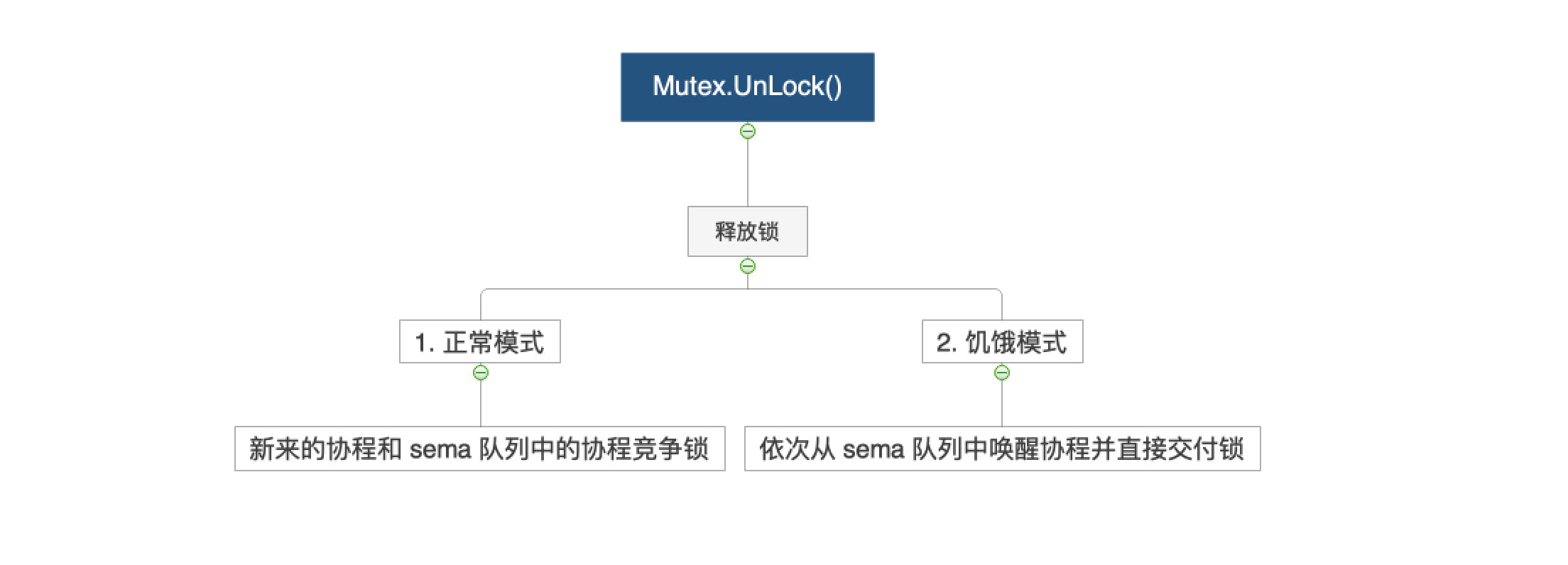
- 正常模式:解锁后新来的协程和 sema 队列中的协程一起竞争;
- 饥饿模式:新来的协程直接入 sema 队列,依次从 sema 队列中唤醒协程并直接交付锁;
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// 1. 释放锁,如果锁完全空闲了,那就直接返回
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// 2. 锁不完全空闲,执行下面方法
m.unlockSlow(new)
}
}
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
// 3. 判断是否饥饿
if new&mutexStarving == 0 {
// 3.1 非饥饿模式
old := new
for {
// 3.2 检查锁状态吗,如
// ① 没有等待中的 goroutine
// ② 其他 goroutine 已经被唤醒或者获得锁了
// 直接返回
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 3.3 锁还没被占有,那就尝试从 sema 队列中唤醒一个 goroutine
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
// 3.4 唤醒失败,再次进入 for 循环尝试
old = m.state
}
} else {
// 3.2 饥饿模式下,按顺序唤醒 sema 队列中的 goroutine
runtime_Semrelease(&m.sema, true, 1)
}
}
# 13.4 sync.RWMutex
原理总结
上写锁:
- 竞争写锁,看看有无读协程:
- 没有读协程的话直接获得写锁;
- 有读协程的话,阻塞后来的读协程,等待当前读协程释放;
解写锁:
- 解写锁,唤醒 readerSem;
上读锁:
- readerCount++,并检查是否有写锁:
- 没有写锁,则上锁完毕;
- 有写锁,则陷入 readerSem,等待写锁释放;
解读锁:
- readerCount --,并检测是否有写协程被阻塞:
- 无,则返回;
- 有,则 readerWait --;判断是否是最后一个释放读锁的协程:
- 不是,则返回;
- 是,则唤醒 writerSem,解锁完毕;
# 13.4.1 概述
- 同时只能有一个 Goroutine 能够获得写锁
- 同时可以有任意多个 Gorouinte 获得读锁
- 同时只能存在写锁或读锁(读和写互斥)
rwm.RLock():上读锁rwm.RUnlock():解读锁rwm.Lock():上写锁rwm.Unlock():解读锁
# 13.4.2 底层
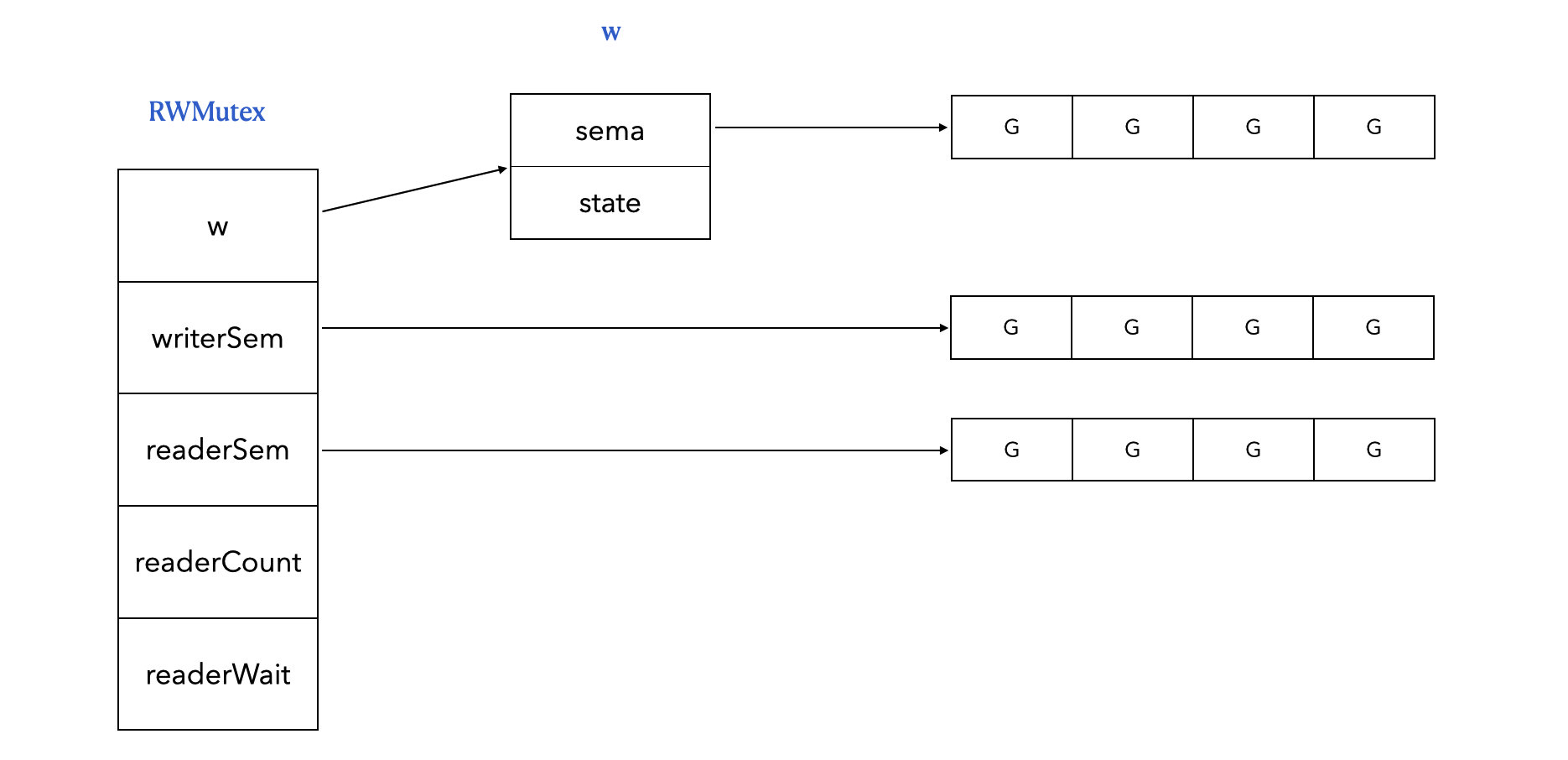
type RWMutex struct {
w Mutex // held if there are pending writers
writerSem uint32 // semaphore for writers to wait for completing readers
readerSem uint32 // semaphore for readers to wait for completing writers
readerCount int32 // number of pending readers
readerWait int32 // number of departing readers
}
w:写锁,拿到它直接有了上写锁的资格,有可能还需要等待读锁全部释放writerSem:写协程等待队列readerSem:读协程等待队列readerCount:正值表示正值读的协程个数,负值表示加了写锁;readerWait:上写锁应该等待读协程的个数
# 13.4.3 上写锁

// Lock locks rw for writing.
// If the lock is already locked for reading or writing,
// Lock blocks until the lock is available.
func (rw *RWMutex) Lock() {
...
// 1. 跟其他的写协程竞争 w 锁
rw.w.Lock()
// 2. readerCount = readerCount - rwmutexMaxReaders
// 并记录原先的值,也就是当前有多少个读协程正在读
// 此处将 readerCount 变为负值,阻塞后来的读协程抢占读锁
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
// 3. 陷入 writerSem,等待 readerWait 个正在读的协程释放读锁
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
// 4. 加锁成功
...
}
# 13.4.4 解写锁

// Unlock unlocks rw for writing. It is a run-time error if rw is
// not locked for writing on entry to Unlock.
//
// As with Mutexes, a locked RWMutex is not associated with a particular
// goroutine. One goroutine may RLock (Lock) a RWMutex and then
// arrange for another goroutine to RUnlock (Unlock) it.
func (rw *RWMutex) Unlock() {
...
// 1. 复原 readerCount,
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 2. 将 readerSem 中想要抢占读锁的协程唤醒
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 3. 释放锁
rw.w.Unlock()
...
}
# 13.4.5 上读锁

// RLock locks rw for reading.
//
// It should not be used for recursive read locking; a blocked Lock
// call excludes new readers from acquiring the lock. See the
// documentation on the RWMutex type.
func (rw *RWMutex) RLock() {
...
// 1. readerCount++,检查是否有写锁
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// 2. 有写锁,则陷入 readerSem,等待写锁释放
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
// 3. 没有写锁或者写锁释放后唤醒 readerSem,则获得读锁成功
...
}
# 13.4.6 解读锁

// RUnlock undoes a single RLock call;
// it does not affect other simultaneous readers.
// It is a run-time error if rw is not locked for reading
// on entry to RUnlock.
func (rw *RWMutex) RUnlock() {
// 1. 释放当前读锁,将 readerCount --
// 2. 检查是否有写协程正在等待
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// 3. 如果有写协程等待,则往下走
rw.rUnlockSlow(r)
}
}
func (rw *RWMutex) rUnlockSlow(r int32) {
// 4. readerWait--
// 5. 判断是否是最后一个释放读锁的协程
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// 6. 是的话,就从 writerSem 中唤醒写协程
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
# 13.5 sync.WaitGroup
# 13.5.1 概述
WaitGroup 等待一组 Goroutine 完成。主 Goroutine 调用 Add 来设置要等待的 Goroutine 的数量。然后每个 Goroutine 运行并在完成时调用 Done。同时,主 Goroutine 可以使用 Wait 来阻塞,直到所有 Goroutine 完成。
wg.Add(delta int):Add 将 delta(可能为负)添加到 WaitGroup 计数器。如果计数器变为 0,所有在 Wait 时阻塞的 Goroutine 将被释放。如果计数器变成负值,Add 会 panic。wg.Done():当 WaitGroup 同步等待组中的某个 Goroutine 执行完毕后,设置这个 WaitGroup 的 counter 数值减 1。wg.Wait():表示让当前的 Goroutine 等待,进入阻塞状态。一直到 WaitGroup 的计数器为 0,才能解除阻塞,这个 Goroutine 才能继续执行。
# 13.5.2 底层
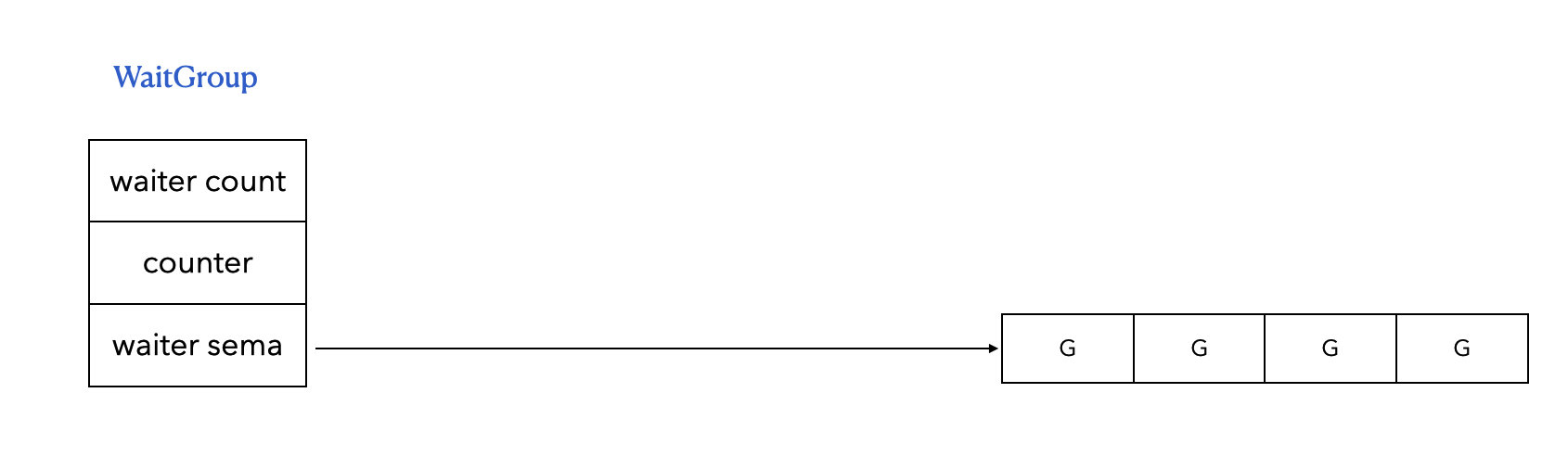
type WaitGroup struct {
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers do not ensure it. So we allocate 12 bytes and then use
// the aligned 8 bytes in them as state, and the other 4 as storage
// for the sema.
state1 [3]uint32
}
noCopy:是 Go 中的一个标记,表示 WaitGroup 只要被用过了,就不可以拷贝,避免出现并发问题。state1:为了兼容 32 位和 64 位机器,用了 3 个 uint32:- state1[0]:waiterCount,等待的协程个数
- state1[1]:counter,被等待的协程个数
- state1[2]:waiter sema,被阻塞的协程
# 13.5.3 wg.Wait()

// Wait blocks until the WaitGroup counter is zero.
func (wg *WaitGroup) Wait() {
// 1. 解析 state1
// statep: 高 32 位 counter,低 32 位 waiter count
// semap: 等待中的协程
statep, semap := wg.state()
...
for {
// 2. 加载 statep
state := atomic.LoadUint64(statep)
v := int32(state >> 32) // counter
w := uint32(state) // waiter count
if v == 0 {
// 3. counter 为 0,则不需要阻塞,返回
...
return
}
// 4. counter 不为 0,则 waitercount++
if atomic.CompareAndSwapUint64(statep, state, state+1) {
...
// 5. 当前协程阻塞,陷入 sema
runtime_Semacquire(semap)
if *statep != 0 {
// 不允许在上一个 Wait 结束之前重用当前 WaitGroup
panic("sync: WaitGroup is reused before previous Wait has returned")
}
...
return
}
}
}
# 15.5.4 wg.Add()

func (wg *WaitGroup) Add(delta int) {
// 1. 解析 staet1
statep, semap := wg.state()
...
// 2. counter += delta
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32) // counter
w := uint32(state) // waiter count
...
// 3. counter 不允许为负
if v < 0 {
panic("sync: negative WaitGroup counter")
}
// 4. Add 和 Wait 不允许并发
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
if v > 0 || w == 0 {
// 5. 如果 counter > 0 或者 waiter count = 0,则直接返回
return
}
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 6. counter = 0 且有 waiter,则释放 sema 中的协程,并重置 waiter count 为 0
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
# 15.5.5 wg.Done()
// Done decrements the WaitGroup counter by one.
func (wg *WaitGroup) Done() {
// 就是执行 counnter--
wg.Add(-1)
}
# 13.6 sync.Once
# 13.6.1 概述
sync.Once 可以让并发中的一段代码只执行一次;
- once.Do(func):执行某一函数,该函数在多个协程中,只会被执行一次。
# 13.6.2 底层
type Once struct {
done uint32
m Mutex
}
done:表示当前 once 是否已经执行过了;m:锁
# 13.6.3 once.Do()
- 实现方式还挺像“双重检查实现单例模式 (opens new window)”

func (o *Once) Do(f func()) {
// Note: Here is an incorrect implementation of Do:
//
// if atomic.CompareAndSwapUint32(&o.done, 0, 1) {
// f()
// }
//
// 上面的实现是错误的
// 它无法保证两个同时竞争的协程中,输的那个阻塞直到成功的那个执行完 f
// 这样多个协程 CAS,会造成性能问题
// 1. 检查 done 是否为 0,不为 0,则说明 f 已经执行过了,直接返回
if atomic.LoadUint32(&o.done) == 0 {
// 2. done 为 0,说明 f 可能还没执行过,往下走
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
// 3. 抢锁,抢不到的话,则说明被其他协程抢去了。
// 然后会被阻塞,这样后面再判断 o.done 的话,就不是 0 了
o.m.Lock()
// 6. 释放锁
defer o.m.Unlock()
// 4. 再次检查 done 是否为 0,不为 0 的话,就是在上锁前已经被执行过了,返回
if o.done == 0 {
// 5. done 还是为 0,可以确保没有执行过,那就先执行 f,再 done = 1
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
# 13.7 如何排查锁异常问题
# 13.7.1 锁拷贝 - go vet
m := sync.Mutex{}
m.Lock()
n := m // n 拷贝 m
m.Unlock()
n.Lock() // 这里会报错,因为 n 在拷贝 m 的时候,把它已经 lock 的状态也拷贝了
这个时候,可以用 Go 提供的 go vet 工具来检查是否存在锁拷贝问题:
➜ go vet main.go
# command-line-arguments
./main.go:16:7: assignment copies lock value to n: sync.Mutex
go vet还能检测可能的 bug 和可疑的构造
# 13.7.2 数据竞争问题 - go build -race
// 此处 i 有并发问题
func add(i *int32) {
*i++
}
func main() {
c := int32(0)
for i := 0; i < 100; i++ {
go add(&c)
}
time.Sleep(time.Second)
}
这个时候,可以用 Go 提供的 go build -race 工具来检查是否存在数据竞争问题:
➜ go build -race main.go
➜ ./main
==================
WARNING: DATA RACE
Read at 0x00c000124000 by goroutine 7:
main.add()
/Users/hedon-/goProjects/leetcode/go_advance/13-mutex/atomic/main.go:6 +0x3a
Previous write at 0x00c000124000 by goroutine 6:
main.add()
/Users/hedon-/goProjects/leetcode/go_advance/13-mutex/atomic/main.go:6 +0x4e
Goroutine 7 (running) created at:
main.main()
/Users/hedon-/goProjects/leetcode/go_advance/13-mutex/atomic/main.go:12 +0x84
Goroutine 6 (finished) created at:
main.main()
/Users/hedon-/goProjects/leetcode/go_advance/13-mutex/atomic/main.go:12 +0x84
==================
Found 1 data race(s)
# 13.7.3 死锁 go-deadlock
https://github.com/sasha-s/go-deadlock