
# 17. 垃圾回收
# 17.1 垃圾回收算法
# 17.1 标记清除法
算法分成 标记 和 清除 两个阶段,先标记出要回收的对象,然后统一回收这些对象。
- 简单。
- 效率不高,标记和清除的效率都不高。
- 标记清除后会产生大量不连续的内存碎片,从而导致在分配大对象时触发 GC。
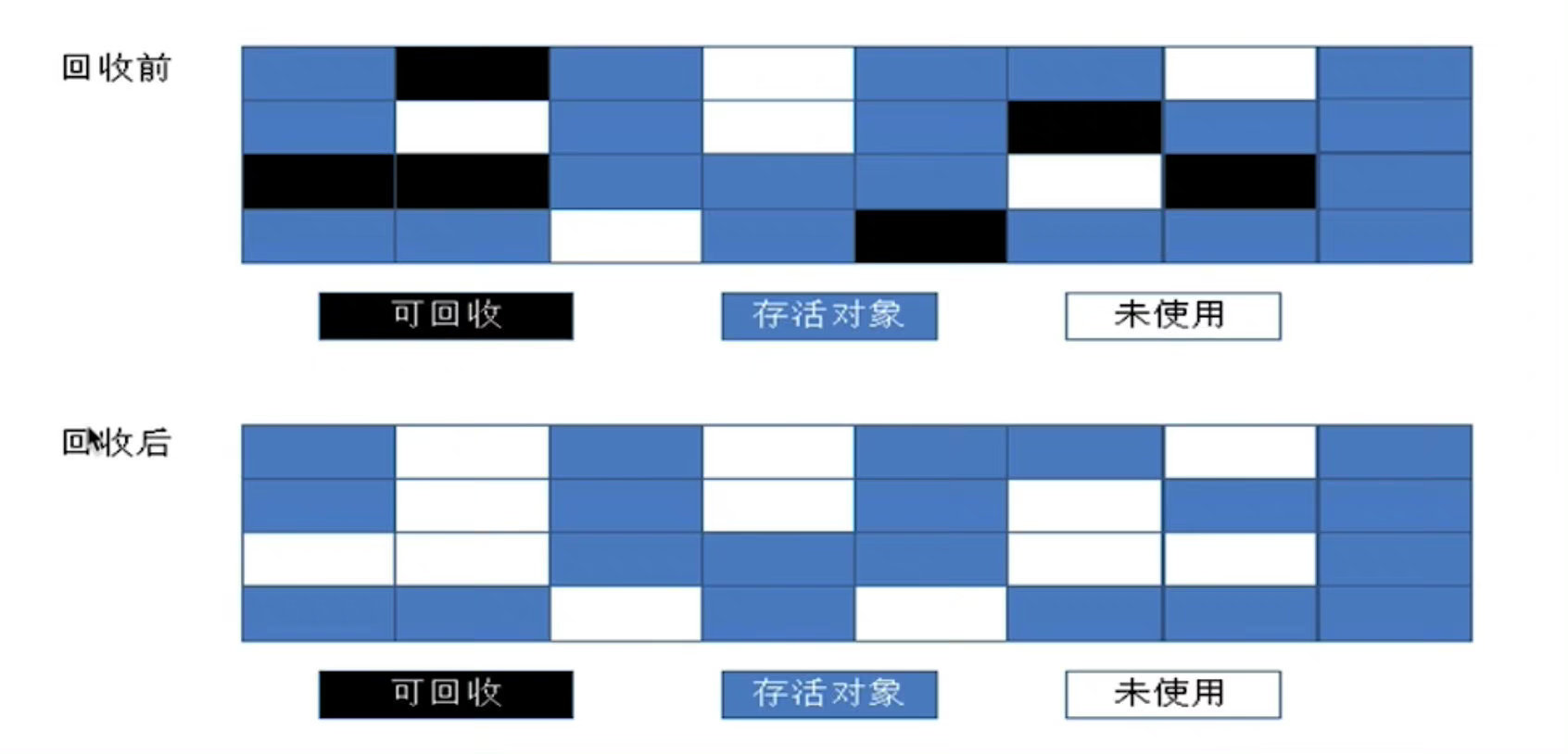
Go 使用的就是标记清除法
虽然普通的标记清除法会造成内存碎片的问题,但是由于 Go 的内存模型中,将内存天然划分成多个 span,所以不存在内存碎片问题。故 Go 用了这种实现简单的标记清除法。
# 17.2 复制算法
把内存分成两块完全相同的区域,每次使用其中一块,当一块使用完了,就把这块上还存活的对象拷贝到另外一块,然后把这块清除掉。
- 实现简单、运行高效,不用考虑内存碎片的问题。
- 内存有些浪费。
JVM 实际实现中,是将内存分为一块较大的 Eden 区和两块较小的 Survivor 空间,每次使用 Eden 和一块 Survivor,回收时,把存活的对象复制到另外一块 Survivor。
HotSpot 默认的 Eden 和 Survivor 比是 8:1,也就是每次能用 90% 的新生代空间。
如果 Survivor 空间不够,就要依赖老年代进行分配担保,把放不下的对象直接进入老年代。
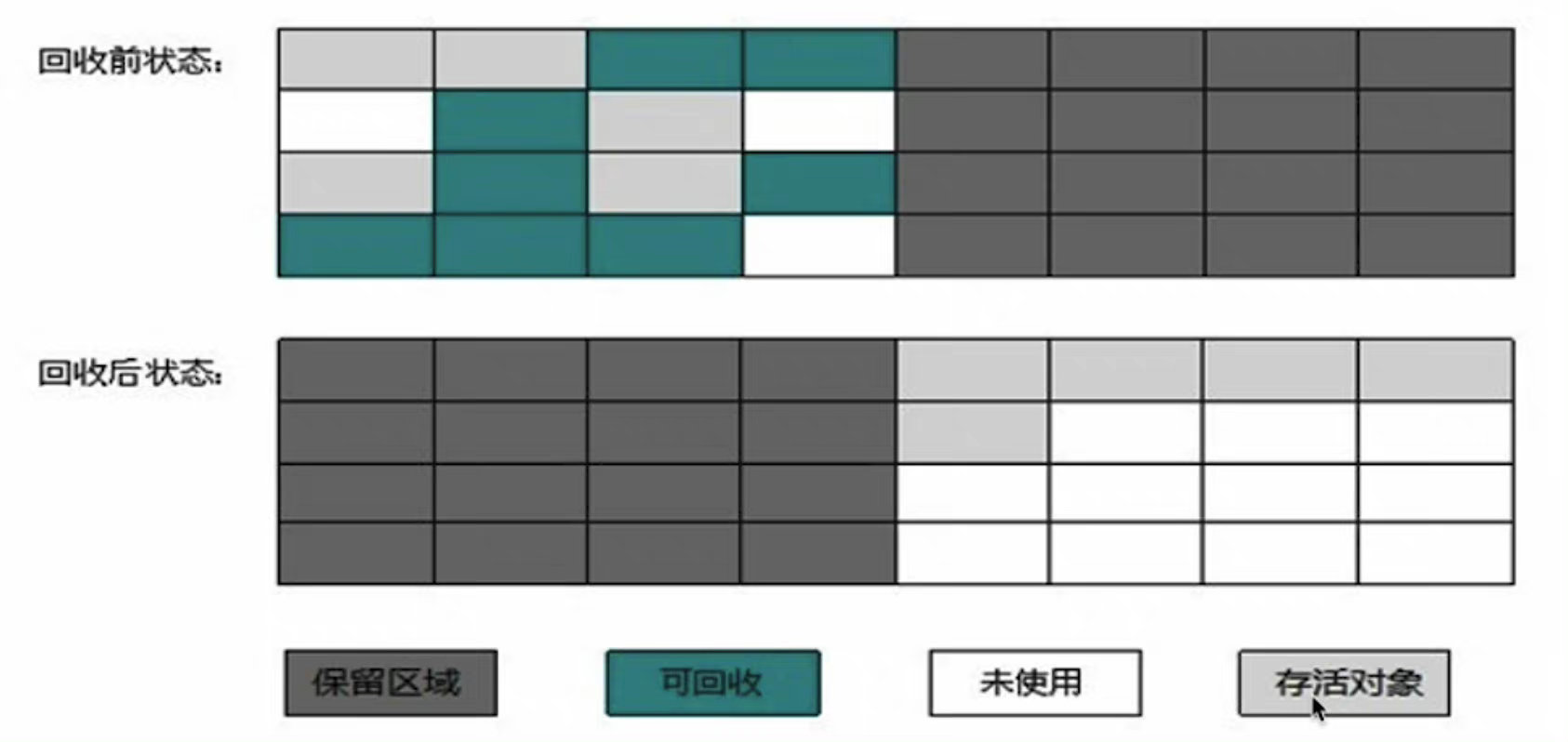
# 17.3 标记整理法
标记过程跟标记清除一样,但后续不是直接清除可回收对象,而是让所有存活对象都向一端移动,然后直接清除边界以外的内存。
标记整理法的开销较大,Java 的老年代就采用标记整理法,因为老年代的 GC 频率较低。
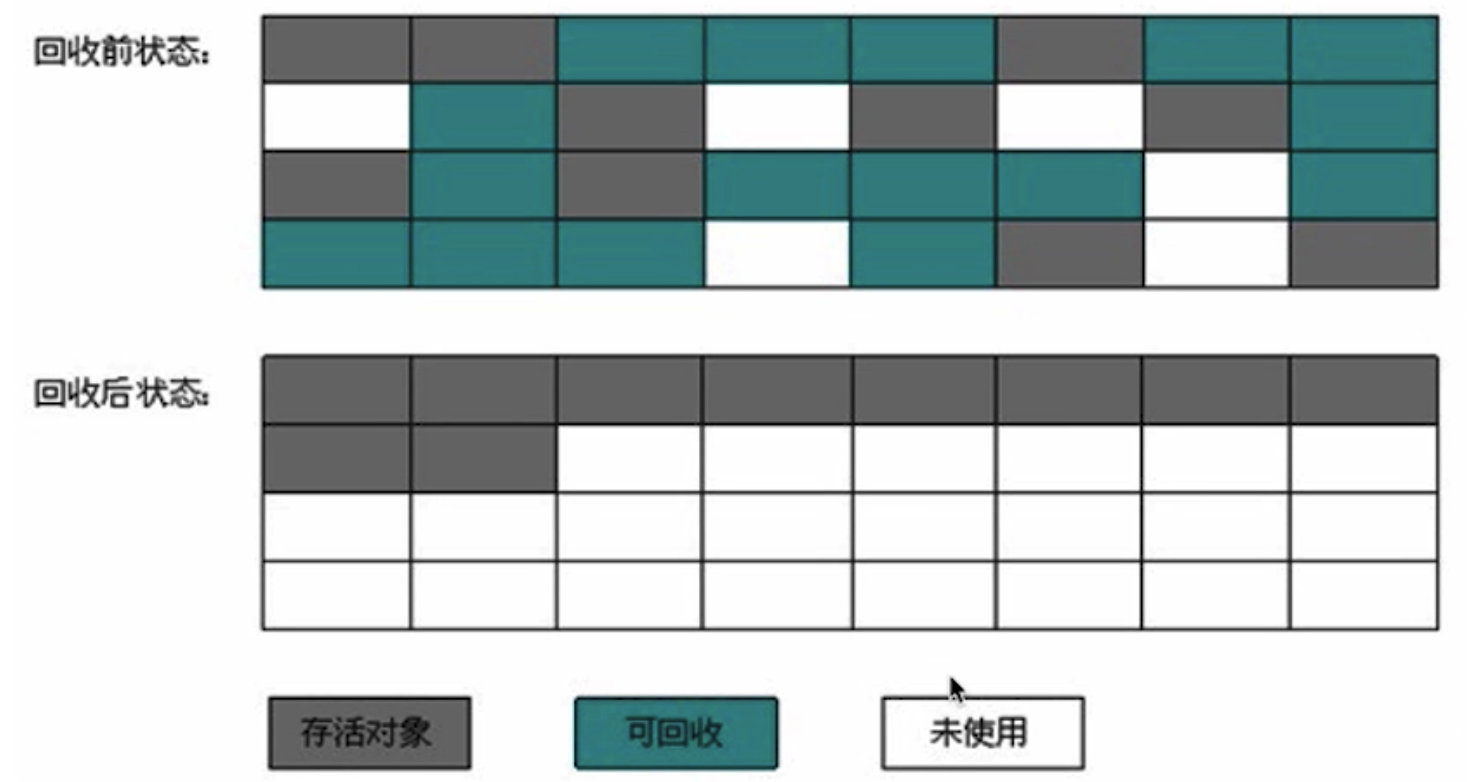
# 17.2 垃圾搜索算法
# 17.2.1 引用计数法
- 给对象添加一个引用计数器,有引用就加 1,引用失效就减 1。
- 回收的时候就看这个计数器是不是 0。
- 实现简单,效率高。
- 需要额外的开销。
- 不能解决对象之间循环引用的问题。
# 17.2.2 根搜索算法

- 从根(GC Roots)节点向下搜索对象节点,搜索走过的路经称为引用链,当一个对象到根之间没有连通的话,则对象不可用。
- 可以作为 GC Roots 的对象:
- 被栈上的指针引用;
- 被全局变量的指针引用;
- 被寄存器中的指针引用;
# 17.2.3 三色标记法
- Go 中使用的就是三色标记法,详细请见下文。(Java 中的 CMS、G1 垃圾回收器也是使用该方法)
# 17.3 串行 GC
Go 很老的版本就采用了最简单的串行 GC:
- Stop The World,暂停其他所有协程;
- 通过根搜索算法,找到无用的堆内存;
- 释放堆内存;
- 恢复所有其他协程;
问题:
- STW 对性能影响非常大;
# 17.4 三色标记法
# 17.4.1 基本原理
Go 将对象用三种颜色来进行标记:
- 黑色:本对象已经被 GC 访问过,且本对象的子引用对象也已经被访问过了
- 灰色:本对象已访问过,但是本对象的子引用对象还没有被访问过,全部访问完会变成黑色,属于中间态
- 白色:尚未被GC访问过的对象,如果全部标记已完成依旧为白色的,称为不可达对象,既垃圾对象
# 17.4.2 基本步骤
- 起初所有堆上的对象都是【白色】的;
- 将 GC Roots 直接引用到的对象挪到【灰色】中;
- 对【灰色】的对象进行根搜索算法:
- 将该对象引用到的其他对象加入【灰色】中;
- 将自己挪到【黑色】中;
- 重复 3 直到【灰色】为空;
- 回收【白色】中的对象。
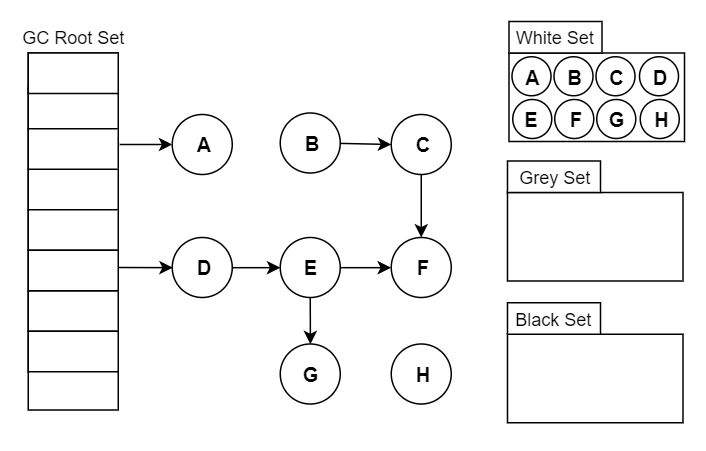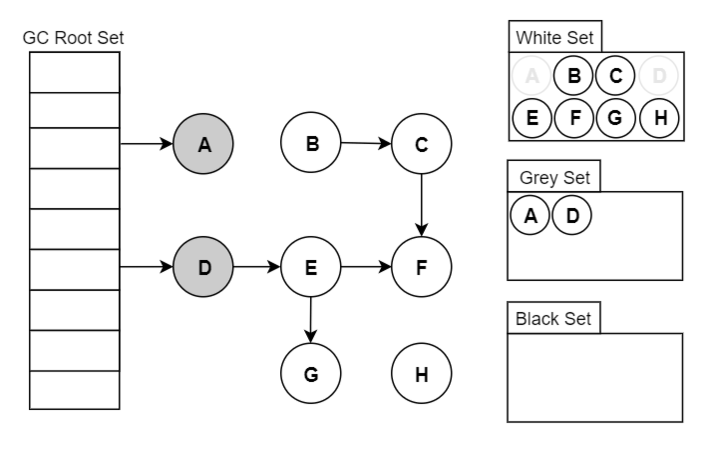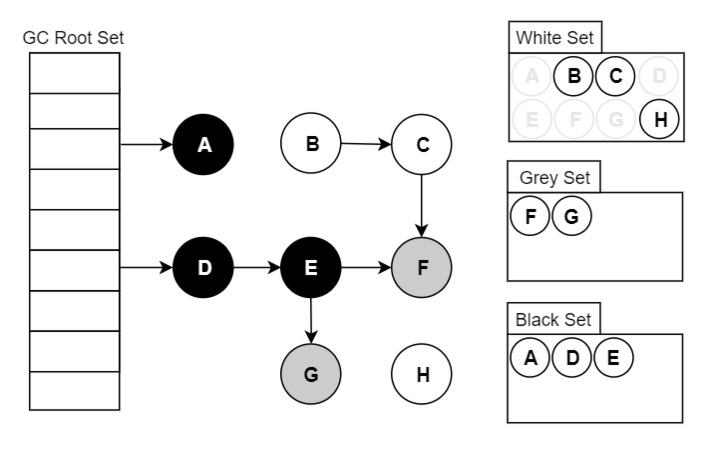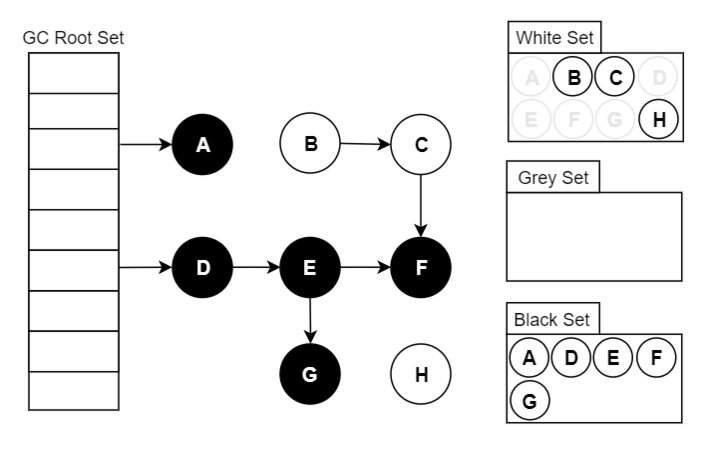
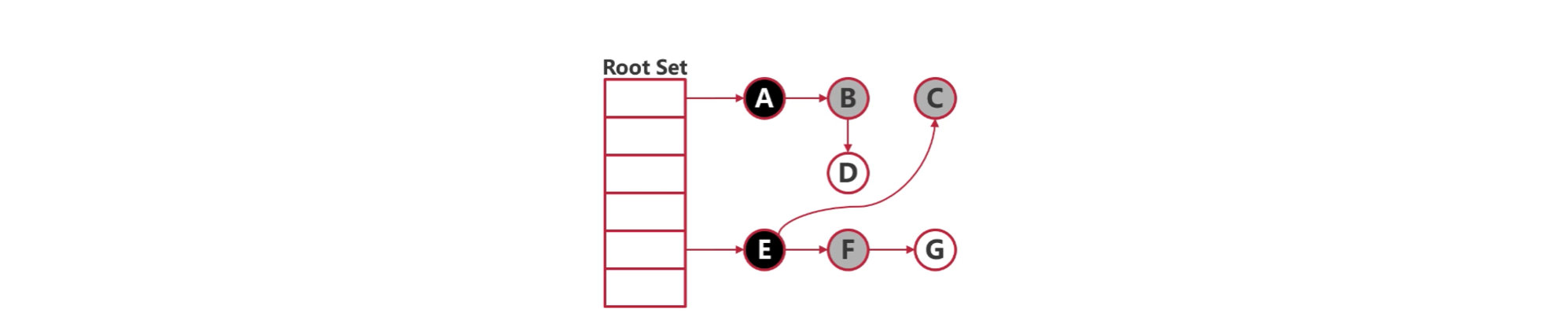
# 17.4.3 删除屏障
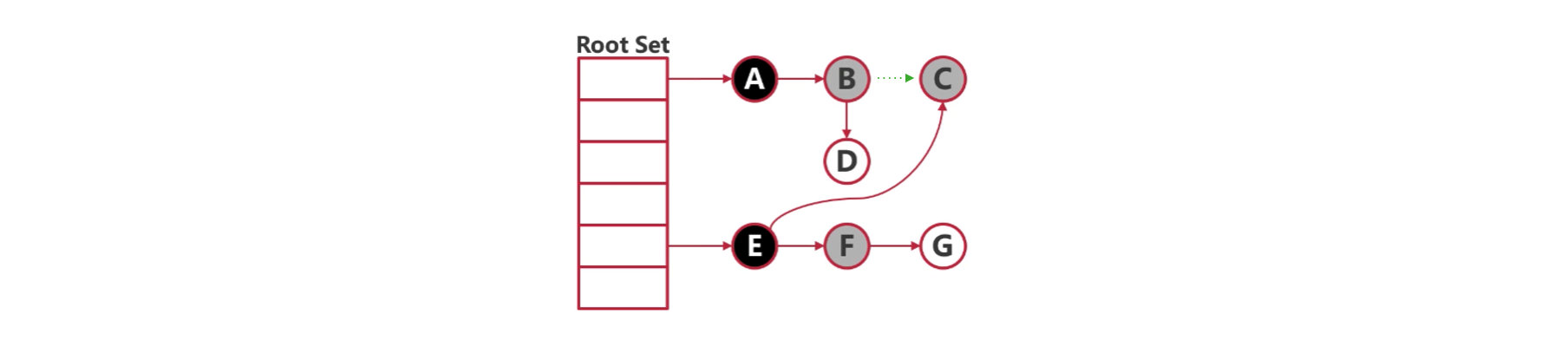
- 并发标记时,对指针释放的白色对象置灰。
这样可以避免在并发 GC 的过程中,由于指针的转移造成对象被误清。
比如一开始 B → C,当 B 在灰色集合的时候,释放了对 C 的指针,但是这个时候有一个在黑色集合的 E 指向了 C,也就是 E → C。由于 E 已经分析过了,所以在对 B 进行分析的时候,就会漏掉 C,导致后面 C 还是在白色集合中,就被误清了。
加入删除屏障后,C 会被强制置灰,就不会误清了。
# 17.4.4 插入屏障
- 并发标记时,对指针新指向的白色对象置灰。
这样可以避免在并发 GC 的过程中,误清掉指针新指向的对象。
比如一开始并没有指向 C 的对象,但是在 GC 过程中,E → C,但是由于 E 已经分析过了,已经进入黑色集合了,所以最后会漏掉 C,导致 C 被误清。
加入插入屏障后,C 会被强制置灰,就不会误清了。
# 17.5 GC 触发时机
# 17.5.1 系统定时触发
- sysmon 会定时检查,如果 2min 内没有进行 gc,那 runtime 就会进行一次 gc。
// runtime/proc.go
// forcegcperiod is the maximum time in nanoseconds between garbage
// collections. If we go this long without a garbage collection, one
// is forced to run.
//
// This is a variable for testing purposes. It normally doesn't change.
var forcegcperiod int64 = 2 * 60 * 1e9
# 17.5.2 用户显示触发
- runtime.GC()
// GC runs a garbage collection and blocks the caller until the
// garbage collection is complete. It may also block the entire
// program.
func GC() {
n := atomic.Load(&work.cycles)
gcWaitOnMark(n)
gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1})
gcWaitOnMark(n + 1)
for atomic.Load(&work.cycles) == n+1 && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
Gosched()
}
for atomic.Load(&work.cycles) == n+1 && atomic.Load(&mheap_.sweepers) != 0 {
Gosched()
}
mp := acquirem()
cycle := atomic.Load(&work.cycles)
if cycle == n+1 || (gcphase == _GCmark && cycle == n+2) {
mProf_PostSweep()
}
releasem(mp)
}
# 17.5.3 申请内存时触发
- mallocgc()
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
// 判断在分配内存的过程中,是否需要 GC
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t) // 开始 GC
}
}
...
}
# 17.6 GC 优化
forcegcperiod不建议修改,因为这个值很难判定哪个好,Go 官方肯定是经过大量实验了,该值是一个比较推荐的值;runtime.GC()不建议主动调用,因为用户很难把握 GC 的时机,过分 GC 有可能造成性能下降;mallocgc()我们也无法修改。
故优化 GC 的思路就是:尽可能少在堆上产生垃圾。
有以下方法:
- 内存池化
- 减少逃逸
- 使用空结构体
# 17.6.1 内存池化
- 适用于缓存性质和经常创建删除的对象。
- 如 channel 的环形缓存,变量永远都占着,不存在回收问题。
# 17.6.2 减少逃逸
- 逃逸会使原本在栈上的对象进入堆中。
- 如 fmt 包,函数返回了指针而不是拷贝,那就有可能会造成逃逸。
# 17.6.3 使用空结构体
- 空结构体不占用内存空间,统一指向
zerobase。 - 如用 Map 来实现 HashSet 的时候,将 value 设置为 struct{}{}。
# 17.7 GC 分析工具
- go tool pprof
- go tool trace
- go build -gcflags -m
- GODEBUG="gctrace=1"
以下面程序为例:
package main
import (
"net/http"
"sync"
_ "net/http/pprof" // pprof 需要
)
func main() {
go func() {
wg := sync.WaitGroup{}
wg.Add(10)
for i := 0; i < 10; i++ {
go func(wg *sync.WaitGroup) {
var counter int
for i := 0; i < 1e10; i++ {
counter++
}
wg.Done()
}(&wg)
}
wg.Wait()
}()
_ = http.ListenAndServe(":8080", nil)
}
go tool pprof
启动程序后,访问:http://127.0.0.1:8080/debug/pprof/heap?debug=1

go build -gcflags -m
➜ 16-gc go build -gcflags -m main.go # command-line-arguments ./main.go:26:25: inlining call to http.ListenAndServe ./main.go:20:12: inlining call to sync.(*WaitGroup).Done ./main.go:15:12: leaking param: wg ./main.go:12:3: moved to heap: wg ./main.go:11:5: func literal escapes to heap ./main.go:26:25: &http.Server{...} escapes to heap ./main.go:15:7: func literal escapes to heapGODEBUG="gctrace=1"
# mac 下 export GODEBUG="gctrace=1" go run main.gogc 1 @0.012s 1%: 0.014+1.1+0.029 ms clock, 0.11+0.28/0.50/0+0.23 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 2 @0.019s 2%: 0.089+0.88+0.093 ms clock, 0.71+0.52/0.65/0+0.75 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 3 @0.025s 2%: 0.11+0.34+0.047 ms clock, 0.90+0.53/0.32/0+0.38 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 4 @0.032s 2%: 0.050+0.20+0.003 ms clock, 0.40+0.28/0.25/0.21+0.026 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 5 @0.069s 1%: 0.046+0.49+0.002 ms clock, 0.36+0.16/0.50/0.55+0.021 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 6 @0.088s 1%: 0.061+0.38+0.017 ms clock, 0.49+0.20/0.36/0.85+0.13 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 7 @0.113s 1%: 0.11+0.83+0.051 ms clock, 0.93+0.19/1.0/1.6+0.41 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 8 @0.142s 1%: 0.075+0.78+0.013 ms clock, 0.60+0.34/0.93/1.7+0.10 ms cpu, 4->4->0 MB, 5 MB goal, 8 P gc 9 @0.170s 1%: 0.10+0.62+0.002 ms clock, 0.80+0.093/0.89/1.6+0.017 ms cpu, 4->4->1 MB, 5 MB goal, 8 P gc 10 @0.192s 1%: 0.092+0.64+0.002 ms clock, 0.74+0.25/0.92/1.9+0.021 ms cpu, 4->4->1 MB, 5 MB goal, 8 P gc 11 @0.209s 1%: 0.051+1.2+0.002 ms clock, 0.41+1.1/1.9/3.0+0.020 ms cpu, 4->4->1 MB, 5 MB goal, 8 P gc 12 @0.235s 1%: 1.4+1.3+0.089 ms clock, 11+1.4/2.1/0.42+0.71 ms cpu, 4->4->2 MB, 5 MB goal, 8 P gc 13 @0.240s 2%: 0.17+0.86+0.021 ms clock, 1.3+0.60/1.3/1.0+0.17 ms cpu, 4->5->2 MB, 5 MB goal, 8 P gc 14 @0.246s 2%: 0.033+0.77+0.019 ms clock, 0.26+0.20/0.91/1.8+0.15 ms cpu, 4->4->1 MB, 5 MB goal, 8 P gc 15 @0.253s 2%: 0.080+0.86+0.019 ms clock, 0.64+0.24/1.3/1.9+0.15 ms cpu, 4->4->2 MB, 5 MB goal, 8 P gc 16 @0.255s 2%: 0.22+2.6+0.002 ms clock, 1.7+0.45/4.8/0.87+0.023 ms cpu, 4->5->2 MB, 5 MB goal, 8 P gc 17 @0.260s 2%: 0.14+1.3+0.033 ms clock, 1.1+0.73/2.1/0+0.26 ms cpu, 5->7->3 MB, 6 MB goal, 8 P gc 18 @0.264s 2%: 0.11+1.3+0.096 ms clock, 0.95+0.87/2.2/0+0.77 ms cpu, 6->8->3 MB, 7 MB goal, 8 P gc 19 @0.267s 2%: 0.079+1.1+0.094 ms clock, 0.63+0.51/1.5/0.73+0.75 ms cpu, 6->7->2 MB, 7 MB goal, 8 P gc 20 @0.273s 3%: 0.081+1.0+0.049 ms clock, 0.65+0.92/1.6/3.5+0.39 ms cpu, 4->4->1 MB, 5 MB goal, 8 P # command-line-arguments gc 1 @0.005s 10%: 0.075+3.2+0.027 ms clock, 0.60+1.4/5.2/3.4+0.21 ms cpu, 4->4->2 MB, 5 MB goal, 8 P gc 2 @0.013s 7%: 0.010+2.5+0.013 ms clock, 0.080+0.76/1.7/4.2+0.10 ms cpu, 6->6->5 MB, 7 MB goal, 8 P gc 21 @0.483s 1%: 0.23+0.72+0.015 ms clock, 1.8+0.17/1.1/2.1+0.12 ms cpu, 4->4->2 MB, 5 MB goal, 8 P # command-line-arguments gc 1 @0.002s 9%: 0.021+2.1+0.026 ms clock, 0.17+0.33/3.1/2.9+0.21 ms cpu, 4->6->5 MB, 5 MB goal, 8 P gc 2 @0.015s 4%: 0.008+1.3+0.013 ms clock, 0.065+0.27/1.5/3.1+0.10 ms cpu, 9->9->7 MB, 11 MB goal, 8 P gc 3 @0.026s 3%: 0.039+0.68+0.011 ms clock, 0.31+0.18/0.99/1.3+0.091 ms cpu, 13->13->11 MB, 14 MB goal, 8 P gc 4 @0.054s 2%: 0.036+0.98+0.011 ms clock, 0.29+0/1.5/1.4+0.091 ms cpu, 22->23->12 MB, 23 MB goal, 8 P gc 5 @0.149s 1%: 0.027+1.5+0.030 ms clock, 0.21+0.58/2.1/1.3+0.24 ms cpu, 24->24->14 MB, 25 MB goal, 8 P GC forced gc 22 @121.134s 0%: 0.41+0.94+0.005 ms clock, 3.3+0/1.7/2.9+0.045 ms cpu, 2->2->1 MB, 5 MB goal, 8 P
← 16. 内存模型 Golang 标准库 →