
# 3. 语法
# 3.1 DCL (Data Control Language)
# 创建用户
CREATE USER '用户'@'主机' IDENTIFIED BY '密码' [WITH max_user_connection n];
CREATE USER 'hedon'@'192.168.0.%' IDENTIFIED BY 'Hedon123!';
# 查询用户
SELECT user,host FROM mysql.user;
# 删除用户
DROP USER '用户名'@'主机';
# 查看用户权限
SHOW grants for '用户名'@'主机';
# 授权
# MySQL 8.0 以上要求 user 必须要存在才能 GRANT
GRANT 权限1,权限2 ON 数据库名.数据库表名 TO '用户名'@'主机' [WITH GRANT OPTION];
# 收回权限
REVOKE 权限 ON 数据库.数据库表 FROM '用户名'@'主机' ;
# 3.2 DDL (Data Definition Language)
# 数据库
查询数据库
show databases;
查询单个数据库
show create database 数据库名;
新增数据库
create database 数据库名;
切换数据库
use 数据库名;
修改数据库
alter database 数据库名 charset 字符集;
清空数据库
truncate database 数据库名;
删除数据库
drop database 数据库名;
# 数据表
新建表
create table imc_course(
course_id INT UNSIGNED auto_increment NOT NULL COMMENT '课程ID',
title VARCHAR(20) NOT NULL DEFAULT '' COMMENT '课程主标题',
title_desc VARCHAR(50) NOT NULL DEFAULT '' COMMENT '课程副标题',
type_id SMALLINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '课程方向ID',
class_id SMALLINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '课程分类ID',
level_id SMALLINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '课程难度ID',
online_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '课程上线时间',
study_cnt INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '学习人数',
course_time TIME NOT NULL DEFAULT '0:00' COMMENT '课程时长',
intro VARCHAR(200) NOT NULL DEFAULT '' COMMENT '课程简介',
info VARCHAR(200) NOT NULL DEFAULT '' COMMENT '学习需知',
harvest VARCHAR(200) NOT NULL DEFAULT '' COMMENT '课程收获',
user_id INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '讲师ID',
main_pic VARCHAR(200) NOT NULL DEFAULT '' COMMENT '课程主图片',
content_score DECIMAL(3,1) NOT NULL DEFAULT 0.0 COMMENT '内容评分',
level_score DECIMAL (3,1) NOT NULL DEFAULT 0.0 COMMENT '简单易懂',
login_score DECIMAL (3,1) NOT NULL DEFAULT 0.0 COMMENT '逻辑清晰',
score DECIMAL(3,1) NOT NULL DEFAULT 0.0 COMMENT '综合评分',
PRIMARY KEY (course_id),
UNIQUE KEY udx_title(title)
)DEFAULT charset=utf8,COMMENT '课程主表'
修改表
alter table
重命名表
rename table 旧表名 TO 新表名;
清空表
truncate table 数据表名;
删除表
drop table [if exists] 数据表名;
# 视图
新建视图
create view view_name
AS
SELECT
#查询语句.....
修改视图
alter view
删除视图
drop view
# 索引
PRIMARY KEY(主键索引)
ALTER TABLE 'table_name' ADD PRIMARY KEY ('column');
UNIQUE KEY(唯一索引)
ALTER TABLE 'table_name' ADD UNIQUE ('column');
INDEX(普通索引)
ALTER TABLE 'table_name' ADD INDEX index_name ('column');
FULLTEXT(全文索引)
ALTER TABLE 'table_name' ADD FULLTEXT ('column');
多列索引
ALTER TABLE 'table_name' ADD INDEX index_name ('column1','column2','column3');
删除索引
drop index
# 3.3 DML(Data Manipulation Language)
# 数据表
插入数据
INSERT INTO 数据表名(字段1,字段2)
VALUES (数据1),(数据2);
INSERT INTO imc_class(class_name)
VALUES ('MYSQL'),('REDIS'),('MONGODB'),('ORACLE');
#当有重复数据段的时候,下面 class_name 是唯一约束,可以使用 ON DUPLICATE KEY UPDATE,会先删除原来的数据,然后插入新的
INSERT INTO imc_class(class_name)
VALUES ('MYSQL')
ON DUPLICATE KEY UPDATE
add_time=CURRENT_TIMESTAMP;
查询数据
select
[distinct] -------------去重
字段名 -------------查询什么字段
from 表名 ------------来自什么表
where 条件语句 ---------条件 # where xxx = null 查不出来,要用 where xxx is (not) null
group by ----------按什么字段分组
having -----------过滤条件
order by XXX asc(desc) -------------排序
limit m,n -----------分页(索引从m开始,第一条索引为0,第2条索引为1;n表示每页显示的数据条数)
group by
注意
group by 必须和
聚合函数结合使用。常见聚合函数:sum(), count(), avg(), min(), max() 等。group by 后边的分组字段要与 select 后边的字段保持一致。
如果过滤分组,则使用
having+过滤条件来完成。
场景:查询每个年级的总人数和班级数量
例如:
select 年级,sum(人数) from 表 group by 年级;
having
having 常常与 group by 一起使用,是对 group by 分组结果再次进行过滤。
having 相当于 where 语句,但 having 可以包含聚合函数,但 where 不可以。
例如:
#例1 select 学号,sum(成绩) from 成绩表 group by 学号 having sum(成绩)>600; #例2 select class_name, level_name, count(*) from imc_course a JOIN imc_class b on a.class_id = b.class_id JOIN imc_level c on c.level_id = a.level_id group by class_name,level_name having count(*)>3;
内关联
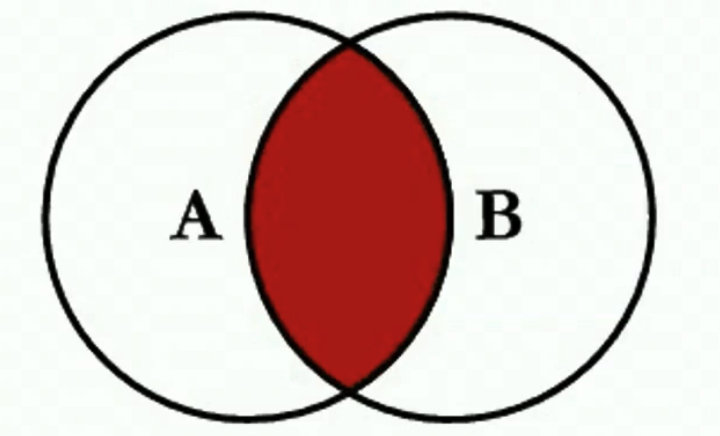
select 字段1,字段2 from TABLEA A inner join TABLEB B on A.Key = B.key;
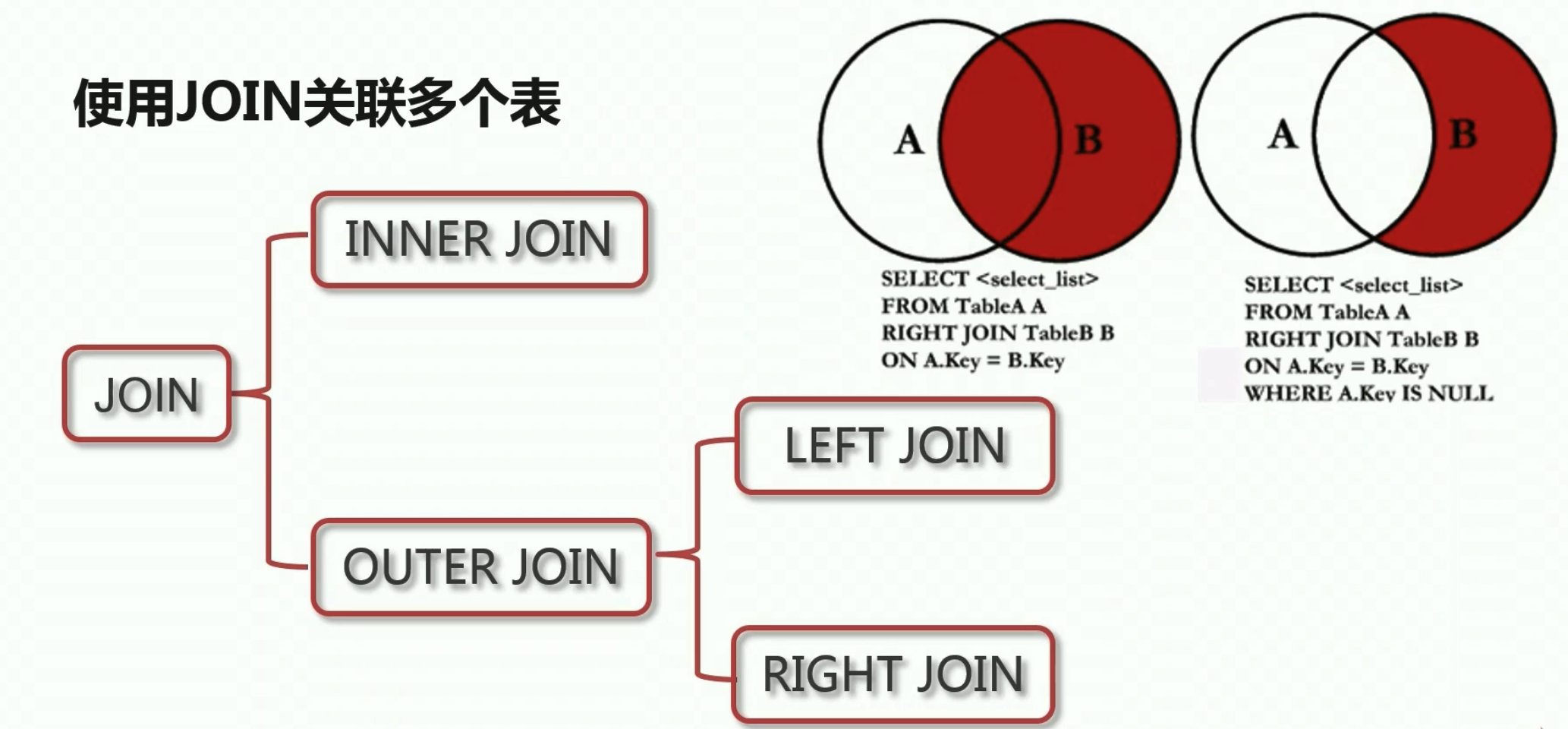
外关联
左外连接:左边的表不加限制,匹配不到,右表为null —— left outer join
右外连接:右边的表不加限制,匹配不到,左表为null —— right outer join
全外连接:所有两个表中的行都会包含在集合中,如果匹配不上,在各自的对应的位置显示 null ——full outer join
select 表1.字段名,表2.字段名 from 表1 left outer join 表2 on 表1.字段=表2.字段;
举例:查询只存在于 a 表但是不存在于 b 表的数据:
select a.course_id, a.title
from imc_course a
left join imc_chapter b on b.course_id = a.course_id
where b.course_id is null;
如果是join,在没有其他过滤条件的情况下 MySQL 会自动选择小表作为驱动表 。
删除数据
DELETE [表名] FROM table_name 条件;
# 删除课程表中没有章节信息的课程
DELETE a
FROM imc_course a
LEFT JOIN imc_chapter b ON b.course_id = a.course_id
WHERE b.course_id IS NULL;
# 删除重复数据,只保留 id 最小的
# 删除课程方向表中重复的课程方向,保留方向ID最小的一条,并在方向名称上增加唯一索引
DELETE a
FROM imc_type a
JOIN(
SELECT type_name,MIN(type_id) AS min_type_id, count(*)
FROM imc_type
GROUP BY type_name having count(*)>1
) b ON a.type_name = b.type_name AND a.type_id > min_type_id;
更新数据
UPDATE 表名 SET col1_name = value1, col2_name = value2 [条件];
# 随机推荐10门课程
UPDATE imc_course
SET is_recommand = 1
ORDER BY rand() #随机函数
LIMIT 10;
# 3.4 TCL(Transaction Control Language)
# 设置事务的隔离级别
SET [PERSIST|SESSION|GLOBAL]
TRANSACTION ISOLATION LEVEL
{
READ UNCOMMITTED|
READ COMMITTED|
REPEATABLE READ|
SERIALIZABLE
}
# 事务过程中的一些指令
BEGIN;
# SQL;
[COMMIT;]
[ROLLBACK;]
# 3.5 聚合函数
| 聚合函数 | 数目 |
|---|---|
| COUNT(*) / COUNT([distince] col) | 计算符合条件的数据行数,distinct 可以去重。 |
| SUM(col_name) | 计算表中符合条件的数值列的合计值。 |
| AVG(col_name) | 计算表中符合条件的数值列的平均值。 |
| MAX(col_name) | 计算表中符合条件的任意列中数据的最大值 |
| MIN(col_name) | 计算表中符合条件的任意列中数据的最小值 |
# COUNT(col)
SELECT COUNT(COLOR='BLUE' OR NULL) AS BLUE,COUNT(COLOR='BLACK' OR NULL) AS BLACK FROM TABLE;
# SUM(col_name)
SELECT SUM(IF(COLOR='BLUE',1,0)) AS BLUE,SUM(IF(COLOR='BLACK',1,0)) AS BLACK FROM TABLE;
# MAX(col_name)
- 查询学习人数最多的课程
select title,study_cnt
from imc_course
where study_cnt = (
select MAX(study_cnt)
from imc_course
);
# 3.6 时间函数
| 函数名 | 说明 |
|---|---|
| CURDATE() / CURTIME() | 返回当前日期 / 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| DATE_FORMAT(date,fmt) | 按照 fmt 的格式,对日期 date 进行格式化 %Y:四位的年 %m:月份(00..12) %d:天(00..31) %H:小时(00..24) %i:分钟(00..59) %s:秒(00..59) |
| SEC_TO_TIME(seconds) | 把秒数转换为(小时:分:秒) |
| TIME_TO_SEC(time) | 把(小时:分:秒)转换为秒数 |
| DATEDIFF(date1,date2) | 返回 date1 和 date2 两个日期相差的天数 |
| DATE_ADD(date,INITERVAL expr unit) | 对给定的日期增加或减少指定的时间单元(unti:DAY天/HOUR小时/MINUTES分钟/SECONDS秒) |
| EXTRACT(unit FROM date) | 提取日期 date 的指定部分 |
| UNIX_TIMESTAMP() | 返回 unix 时间戳(从1970年1月1号到当前时间经过的秒数) |
| FROM_UNIXTIME() | 把 unix 时间戳转换为日期时间 |
| CURRENT_TIMESTAMP() | 插入数据时自动赋值为当前时间 |
| ON UPDATE CURRENT_TIMESTAMP() | 更新数据时自动刷新时间为当前时间 |
# 格式化当前时间
SELECT DATE_FORMAT(NOW(),'%Y%m%d %H:%i:%s');
# 在当前时间加一天
SELECT NOW(), DATE_ADD(NOW(),INTERVAL 1 DAY);
# 在当前时间减去1小时30分钟
SELECT NOW(), DATE_ADD(NOW(), INTERVAL '-1:30' HOUR_MINUTE);
# 提取日期中的年份/日期
SELECT NOW(), EXTRACT(YEAR FROM NOW()), EXTRACT(DAY FROM NOW());
# 3.7 字符串函数
| 函数名 | 说明 |
|---|---|
| CONCAT(str1,str2,...) | 把 str1、str2、.. 连接成一个字符串 |
| CONCAT_WS(sep,str1,str2,..) | 用指定的分隔符 sep 连接字符串 |
| CHAR_LENGTH(str) | 返回字符串 str 的字符个数 |
| LENGTH(str) | 返回字符串 str 的字节个数 |
| FORMAT(X,D[,locale]) | 将数字字符串 X 格式化为格式,如"#,###,###.##",并舍入到 D 位小数 |
| LEFT(str,len) / RIGHT(str,len) | 从字符串的左/右边起返回 len 长度的子字符串 |
| SUBSTRING(str,pos,[len]) | 从字符串 str 的 pos 位置起(从1开始)返回长度为 len 的子串 |
| SUBSTRING_INDEX(str,delim,count) | 返回字符串 str 按 delim 分割的前 count 个子字符串 |
| LOCATE(substr,str) | 在字符串 str 中返回子串 substr 第一次出现的位置(从0开始) |
| TRIM([remstr FROM] str) | 从字符串 str 两端删除不需要的字符 remstr |
# 合并字符串
SELECT CONCAT(class_name,title),CONCAT_WS('---',class_name,title)
FROM imc_course a
JOIN imc_class b ON b.class_id = a.class_id;
# 格式化数字
SELECT FORMAT(123456.789,4);

# 3.8 其他函数
| 函数名 | 说明 |
|---|---|
| ROUND(X,D) | 对数值 X 进行四舍五入保留 D 位小数 |
| RAND() | 返回一个在 0 和 1 之间的随机数 |
| CASE WHEN [condition] THEN result [WHEN [condition] THEN result ...] END | case 语句 |
| IF(expr, resIfTure, resIfFalse) | if 语句 |
| MD5(str) | 返回 str 的MD5 值 |
# 将男的都是变成女的,女的都变成男的
UPDATE imc_user
SET sex = (
CASE
WHEN sex = 1 THEN 0
ELSE 1
END
);