
# 7. SQL 优化
总结
- 慢日志查询慢 SQL / 数据库实时监控长时间运行的 SQL。
- 使用 explain 工具分析 SQL。
- 修改 SQL,让 SQL 尽可能走索引。
- 垂直切分/水平切分。
# 7.1 通过慢查询日志发现问题
# 7.1.1 配置 MySQL 慢查询日志
默认情况下不开启。
# 启动
SET global slow_query_log = [ON | OFF];
# 指定慢查询日志存放位置(可不配置)
SET global slow_query_log_file = /sql_log/showlog.log;
# 指定“慢”的条件
SET global long_query_time = xx.xxx秒;
# 指定要记录所有未使用索引的 SQL
SET global log_queries_not_using_indexes = [ON | OFF];
# 7.1.2 分析 MySQL 慢查询日志
# MySQL 官方分析工具
mysqldumpslow [option] [logs];
# 第三方工具 Percona Toolkit
pt-query-digest [OPTION] [FILES] [DSN];
# 7.2 实时监控 SQL 情况
SELECT id,`user`,`host`,DB,command,`time`,state,info
FROM information_schema.PROCESSLIST
WHERE TIME >= 60 #毫秒
# 7.3 分析 SQL 执行计划
# 7.3.1 为什么要关注执行计划
- 了解 SQL 如何访问表中的数据。
- 了解 SQL 如何使用表中的索引。
- 了解 SQL 所使用的查询类型。
# 7.3.2 EXPLAIN 获取执行计划
可以使用 explain 工具获取执行计划
EXPLAIN
# connection_id 就是用前面实时监控的 PROCESSLIST 中的 connection_id
{explainable_stmt | FOR CONNECTION connection_id}
explainable_stmt:{
SELECT statement |
DELETE statement |
INSERT statement |
UPDATE statement |
REPLACE statement
}
举例:
EXPLAIN
SELECT class_id FROM imc_course
WHERE class_id IN (SELECT class_id FROM imc_user);
# 7.3.3 分析思路
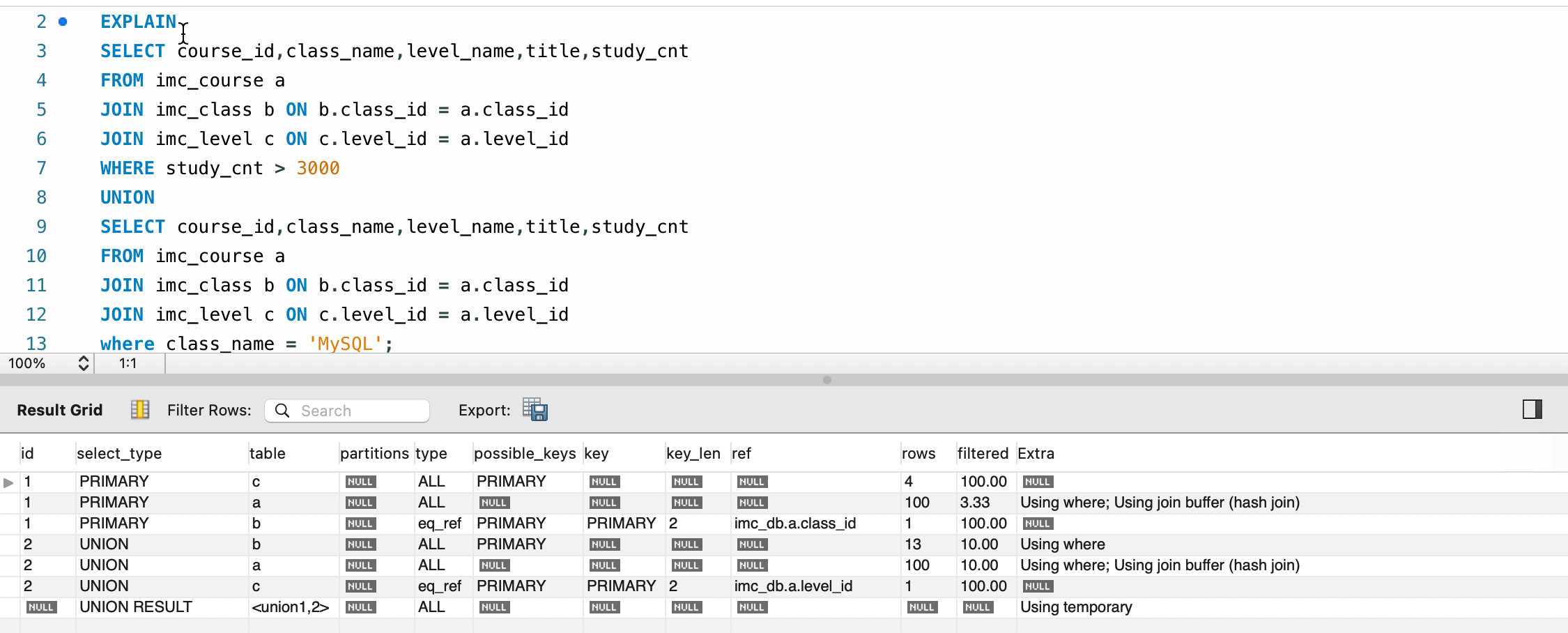
# id
id 可以认为是查询序列号,每一个 id 代表一个 select,一组相同的 id 可以认为是一个查询里分开进行的几步(如关联查询),解析顺序在 explain 生成表中由上至下顺序解析,不同的 id 代表不同子查询,id 越大优先级越高,越先被解析。
- ID 相同时由上到下执行,我们应该由上至下来分析
- ID 不同时,由大到小执行,我们应该由大到小来分析。
# select_type
| 值 | 含义 |
|---|---|
| SIMPLE | 简单查询,不包含子查询或是 UNION 操作的查询。 |
| PRIMARY | 查询中如果包含任何子查询,那么最外层的查询则被标记位 PRIMARY。 |
| SUBQUERY | SELECT 列表中的子查询。 |
| DEPENDENT SUBQUERY | 依赖外部结果的子查询。 |
| UNION | union 操作的第二个或是之后的查询的值为 UNION。 |
| DEPENDENT UNION | 当 union 作为子查询时,第二或是第二个后的查询就为 DEPENDENT UNION。 |
| UNION RESULT | UNION 产生的结果集。 |
| DERIVED | 出现在 FROM 子句中的子查询。 |
# table
- 表明
- 表别名
- <union[查询ID],[查询ID]...>
# partitions
- 对于分区表,显示查询的分区ID。
- 没有分区的话,默认为 NULL。
# type
type表示 MySQL 访问数据方式。
| 性能 | 值 | 含义 |
|---|---|---|
| 高 | system | 这是 const 联接类型的一个特例,当查询的表只有一行时使用。 |
| const | 表中有且只有一个匹配的行时使用,如对主线或是唯一索引的查询,这是效率最高的联接方式。 | |
| eq_ref | 唯一键或主键索引查找,对于每个索引键,表中只有一条记录与之匹配。 | |
| ref | 非唯一索引查找,返回匹配某个单独值的所有行。 | |
| ref_or_null | 类似于 ref 类型的查询,但是附加了对 NULL 值列的查询。 | |
| index_merge | 表示使用了索引合并优化方法。 | |
| range | 索引范围查找,常见于 between、>、< 这样的查询条件。 | |
| index | FULL index Scan 全索引查找,同 ALL 的区别是:遍历的是索引树。 | |
| 低 | All | FULL TABLE Scan 全表扫描,效率最差。 |
# possible_keys
指出 MySQL 在查询中可能会使用的索引,但不一定会使用,MySQL 会根据统计信息选出代价最小的索引。代价一般指找到所需的行记录所需要查询的页数量(并不是行数量,因为 MySQL 以页为基本单位,可能会出现行数较少,但是需要 I/O 的页却较多的情况),页的数量越多代价越大,性能也就越差。
# key
在查询中实际使用的索引,若没有使用则显示 NULL。根据官方文档,key 中实际使用的索引可能并不会在 possible_keys 中出现,当某个索引是需要查找的列的覆盖索引,且 MySQL 找不到更好的索引去查询时,会使用该索引进行索引全表扫描,虽然比较慢,但总比普通的全表扫描,且需要随机磁盘I/O好得多。
# key_len
表示使用的索引在表定义中的长度,比如 film 表中主键为 smallint,则为 2,language_id 为 tinyint 则为1,若没有使用索引,则为NULL。通过 key_len 可以知道复合索引中的那几列在查询中使用了。
所以我们定义的索引列的长度最好是刚好能满足需求的长度,这样可以减少索引长度。
# ref
指出哪些列或常量被用于索引查找。
如果是使用的常数等值查询,这里会显示 const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为 func。
# rows
表示优化器认为需要扫描多少行才能得到目标结果。对于 InnoDB 来说这是一个估计值,InnoDB 并不知道一页中有多少行数据,因而优化器会通过随机读取一些页求平均值来估计行数。
# filtered
表示 MySQL 预估的返回的数据集的行数占其扫描的行数的百分比。
# Extra
这是 MySQL 认为很关键,但是又不应该出现在前面所述字段的信息。
| 值 | 说明 |
|---|---|
| Distinct | 优化 distinct 操作,在找到第一匹配的元素后即停止找同样值的动作。 |
| Not exists | 使用 not exists 来优化查询。MySQL 能够从一个查询中使用一个 left join 优化,当从该表中找到一行数据与已找出数据行对应,则不再查找更多行。 |
| Using filesort | 当排序不能使用索引时出现,需要产生临时表进行排序。 当临时表较小时,存储在内存中用快速排序进行排序,当临时表较大时则分段存储在硬盘中,每段快速排序,然后在内存中合并排序。 排序算法有两种,一种排序时仅用需要排序的字段,这样可以存储更多的行在内存中,但缺点是需要两次传输;一种是排序时把所有列都传输过来,只需要一次传输,但内存消耗较大。 当查询所有列长度不超过 max_length_for_sort_data 时用单次传输排序,超过则两次传输排序。 长用在 order by、group by、limit 查询中。 |
| Using index | 获取查询所需列仅需要从索引中即可获取,不需要从磁盘中 I/O 获取。即使用了覆盖索引,可以大大减少 I/O 所消耗的时间,提高效率。对于 InnoDB 来说,次级索引可以由此获益,从而可以不用多查询一次主键索引表。 |
| Using temporary | MySQL 需要使用临时表来处理查询,常见于排序、子查询和分组查询。 |
| Using where | 需要在 MySQL 服务器层使用 WHERE 条件来过滤数据。 |
| select tables optimized away | 直接通过索引来获得数据,不用访问表。 |
| constrow not found | 当所查找的表为空时出现。 |
| impossiblewhere | 当 WHERE 条件不可能发生时出现。 |
| deletingall rows | 某些引擎支持一种更快的删除所有行记录的方法,比如 MyISAM引擎表,我猜是因为 MyISAM 将数据单独放在一个文件的原因。 |
| impossiblehaving | 类似 impossible where。having 条件过滤没有结果,或者始终宣布出任何列(直接返回已有查询的结果集)。 |
| loosescan | 半连接优化的 loosescan 机制被启用。loosescan 子查询中的字段作为一个索引且外部 select 语句可以与很多的内部 select 记录相匹配,从而便有通过索引堆记录进行分组的效果。 |
| notable used | 查询只有一个from dual,没有真实表的from条件。 |
| usingMRR | 优化器通过 MRR(Multi-Range ReadOptimization)算法读取表数据。MRR 通过将随机 I/O 转换为顺序 I/O 以降低查询过程中的 I/O 开销。对于次级索引,先将次级索引表得到的次级索引和主键的结果集根据主键排序,然后在主键索引表中访问时就变成了顺序I/O。 |
# 7.4 优化
# 7.4.1 优化索引
# ① 应该在哪些列上建立索引
筛选性越强的,越排在前面。
- WHERE 字句中的列。
- ORDER BY,GROUP BY,DISTINCT 中的字段。
- 多表 JOIN 的关联列。
示例:查询出2019年1月1号以后注册的男性会员的昵称。(显然日期的筛选性要比性别更好)
没建立索引:
SELECT user_nick FROM imc_user WHERE sex = 1 AND reg_time > '2019-01-01';总共查询了 2530 行。

建立索引:index_sex_regtime
ALTER TABLE imc_user ADD INDEX idx_sex_regtime (sex,reg_time);总共查了 2530 行,根本没作用。

建立索引:index_regtime_sex
# 先删除之前的索引 ALTER TABLE imc_user DROP INDEX idx_sex_regtime; # 再建立新的索引 ALTER TABLE imc_user ADD INDEX idx_regtime_sex (reg_time,sex);总共查了 516 行,效果好了很多。

# ② 如何选择复合索引键的顺序
- 区分度最高的列放在最左侧。
- 使用频率最多的列放在最左侧。
- 占用空间最小的列放在最左侧。
# ③ 索引使用的误区
- 索引越多越好❌
- 使用 IN 列表查询不能使用索引❌
- 查询过滤条件顺序必须跟索引顺序一样❌
# 7.4.2 改写 SQL
# ① 改写原则
- 使用 outer join 代替 not in(这样可以走索引)。
- 使用 CTE 代替子查询。
- 拆分复杂的大 SQL 为多个简单的小 SQL。
# ② 巧用计算列优化查询
示例:查询对于内容、逻辑、难度三项评分之和大于28分的用户评分。
没建索引
explain SELECT * FROM imc_classvalue WHERE (content_score + level_score + logic_score) > 28;
建索引:idx_content_level_logic,发现索引是无效的。
ALTER TABLE imc_classvalue ADD INDEX idx_content_level_logic (content_score,level_score,logic_score); explain SELECT * FROM imc_classvalue WHERE (content_score + level_score + logic_score) > 28;
新加一个字段,表示这三项之和,然后再在这个字段建索引。这样就只需要查询 51 行了。
# 先删除之前的索引 ALTER TABLE imc_classvalue DROP INDEX idx_content_level_logic; # 加新字段 ALTER TABLE imc_classvalue ADD COLUMN total_score DECIMAL(3,1) AS (content_score + level_score + logic_score); # 在新字段上建索引 ALTER TABLE imc_classvalue ADD INDEX idx_total_score(total_score); explain SELECT * FROM imc_classvalue WHERE total_score > 28;