
# 七、Redis 主从复制
# 1. 主从复制

- Master:负责写
- Slave:负责读
# 2. 环境搭建
# 2.1 准备环境
| IP | 角色 | 操作系统 |
|---|---|---|
| 172.16.58.200 | redis-master | CentOS 7 |
| 172.16.58.201 | redis-slave1 | CentOS 7 |
| 172.16.58.202 | redis-slave2 | CentOS 7 |
# 2.2 下载 Redis
分别在三台机器上下载 Redis:Redis 安装
# 2.3 创建配置/数据/日志目录
分别在三台机器上运行以下命令:
# 创建配置目录
mkdir -p /usr/local/redis/conf
# 创建数据目录
mkdir -p /usr/local/redis/data
# 创建日志目录
mkdir -p /usr/local/redis/log
# 2.4 新建配置文件
三台机器都创建一份新的 redis.conf
vim /usr/local/redis/conf/redis.conf
redis-master 写下以下内容:
# 放行 IP 访问限制
bind 0.0.0.0
# 后台启动
daemonize yes
# 日志存储目录及日志名
logfile "/usr/local/redis/log/redis.log"
# rdb 数据文件名
dbfilename dump.rdb
# aof 模式开启和 aof 数据文件名
appendonly yes
appendfilename "appendonly.aof"
# rdb 数据文件和 aof 数据文件的存储目录
dir /usr/local/redis/data
# 设置密码
requirepass 123456
# 从节点访问主节点密码(必须与 requirepass 一致)
masterauth 123456
# 从节点只读模式
replica-read-only yes
redis-slave1 和 redis-slave2 写下以下内容:
# 放行 IP 访问限制
bind 0.0.0.0
# 后台启动
daemonize yes
# 日志存储目录及日志名
logfile "/usr/local/redis/log/redis.log"
# rdb 数据文件名
dbfilename dump.rdb
# aof 模式开启和 aof 数据文件名
appendonly yes
appendfilename "appendonly.aof"
# rdb 数据文件和 aof 数据文件的存储目录
dir /usr/local/redis/data
# 设置密码
requirepass 123456
# 从节点访问主节点密码(必须与 requirepass 一致)
masterauth 123456
# 从节点只读模式
replica-read-only yes
# 从节点属于哪个指定主节点
slaveof 172.16.58.200 6379
# 2.5 启动 Redis
在三台机器上都启动 Redis
# 先看看之前有没有运行 redis
ps -ef | grep redis
# 杀死进程
kill -9 PID
# 启动新 redis
redis-server /usr/local/redis/conf/redis.conf
# 检查 redis 启动情况
ps -ef | grep redis
# 2.6 查看集群状态
核心命令:info replication
# 在 redis-master 节点上连接 redis
redis-cli -a 123456
# 查看 redis 集群信息
127.0.0.1:6379> info replication
# 输出
role:master
connected_slaves:2
slave0:ip=172.16.58.201,port=6379,state=online,offset=168,lag=1
slave1:ip=172.16.58.202,port=6379,state=online,offset=168,lag=1
master_replid:84c5932a0eab5b1eae6bb1721dbfecb1dc91e925
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:168
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:168
# 2.7 测试集群功能
redis-master
# 可写 127.0.0.1:6379> set username zhangsan OK # 可读 127.0.0.1:6379> get username "zhangsan"redis-slave1 & redis-slave2
# 读得到 zhangsan,说明主从复制成功 127.0.0.1:6379> get username "zhangsan" # 写不了,因为从节点只能读 127.0.0.1:6379> set username lisi (error) READONLY You can't write against a read only replica.
# 3. 原理剖析
# 3.1 info replication 信息详解
| 角色 | 属性名 | 属性描述 |
|---|---|---|
| 通用配置 | role | 节点的角色 |
| repl_backlog_active | 复制缓冲区状态 | |
| repl_backlog_size | 复制缓冲区尺寸(单位:字节) | |
| repl_backlog_firstbyte_offset | 复制缓冲区起始偏移量,标识当前缓冲区可用范围 | |
| repl_backlog_hitslen | 复制缓冲区已存有效数据长度 | |
| master_replid | 当前主节点 ID | |
| master_replid2 | 上一任主节点 ID | |
| master_repl_offset | 主节点偏移量 | |
| second_repl_offset | 记录上一个主节点已经写入了偏移量,便于从节点与主节点重新建立连接的时候不需要全量复制 | |
| 主节点 | connected_slaves | 连接的从节点个数 |
| slave0 | 连接的从节点信息 | |
| master_repl_offset | 主节点偏移量 | |
| 从节点 | master_host | 主节点 IP |
| master_port | 主节点端口 | |
| master_link_status | 与主节点的连接状态 | |
| master_last_io_seconds_ago | 主节点最后与从节点的通信时间间隔,单位是秒 | |
| master_sync_in_progress | 从节点是否正在全量同步主节点 RDB 文件 | |
| slave_repl_offset | 从节点复制偏移量 | |
| slave_priority | 从节点选举优先级 | |
| slave_read_only | 从节点是否只读 | |
| connected_slaves | 连接的从节点个数 |
# 3.2 复制流程
# 3.2.1 日志分析
查看
redis-master日志tail -f -n 800 /usr/local/redis/log/redis.log关注下面日志
# 主节点已就绪,等待从节点连接 21279:M 03 Aug 2021 20:00:49.285 * Ready to accept connections # 172.16.58.201:6379 redis-slave1 节点发起 sync 全量复制请求 21279:M 03 Aug 2021 20:02:28.358 * Replica 172.16.58.201:6379 asks for synchronization 21279:M 03 Aug 2021 20:02:28.358 * Full resync requested by replica 172.16.58.201:6379 # 创建缓冲区,新建一个新的 replication id 21279:M 03 Aug 2021 20:02:28.358 * Replication backlog created, my new replication IDs are '84c5932a0eab5b1eae6bb1721dbfecb1dc91e925' and '0000000000000000000000000000000000000000' # 使用 bgsave 将数据写到磁盘 21279:M 03 Aug 2021 20:02:28.358 * Starting BGSAVE for SYNC with target: disk 21279:M 03 Aug 2021 20:02:28.359 * Background saving started by pid 21738 # 写完 21738:C 03 Aug 2021 20:02:28.360 * DB saved on disk # 写了多少数据 21738:C 03 Aug 2021 20:02:28.360 * RDB: 0 MB of memory used by copy-on-write # 退出写数据 21279:M 03 Aug 2021 20:02:28.420 * Background saving terminated with success # 172.16.58.201:6379 redis-slave1 全量复制完成 21279:M 03 Aug 2021 20:02:28.421 * Synchronization with replica 172.16.58.201:6379 succeeded # 172.16.58.202:6379 redis-slave2 节点请求全量复制请求 21279:M 03 Aug 2021 20:02:29.443 * Replica 172.16.58.202:6379 asks for synchronization # 下面同理 21279:M 03 Aug 2021 20:02:29.443 * Full resync requested by replica 172.16.58.202:6379 21279:M 03 Aug 2021 20:02:29.443 * Starting BGSAVE for SYNC with target: disk 21279:M 03 Aug 2021 20:02:29.444 * Background saving started by pid 21747 21747:C 03 Aug 2021 20:02:29.445 * DB saved on disk 21747:C 03 Aug 2021 20:02:29.445 * RDB: 0 MB of memory used by copy-on-write 21279:M 03 Aug 2021 20:02:29.524 * Background saving terminated with success 21279:M 03 Aug 2021 20:02:29.525 * Synchronization with replica 172.16.58.202:6379 succeeded
# 3.2.2 全量复制
- 全量复制一般是 Slave 刚开始连接 Master 后做的数据同步过程。
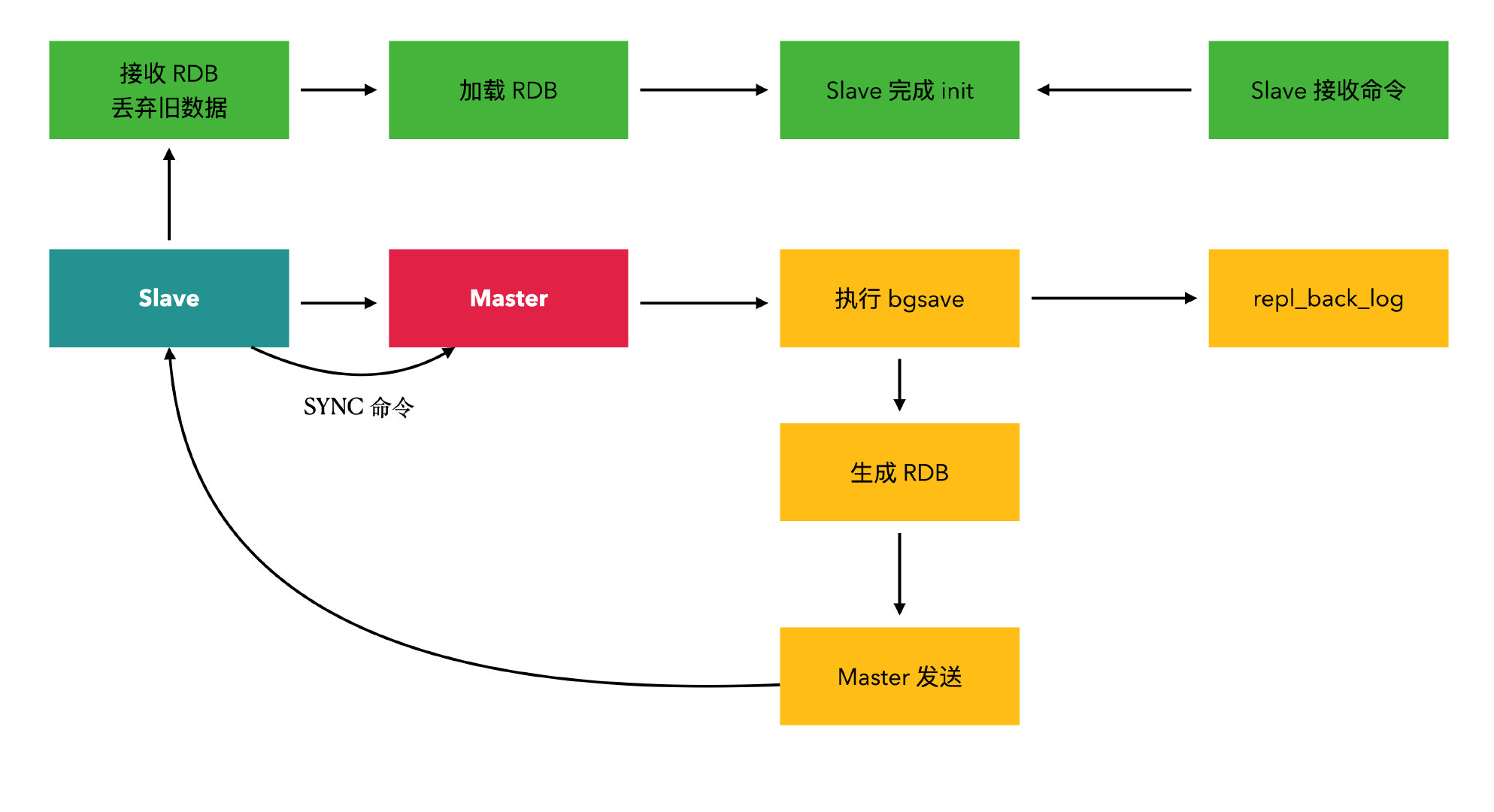
# 3.2.3 增量复制
- 增量复制是 Slave 初始后开始正常工作时 Master 发生写操作时同步到 Slave 的过程。
- 从节点与主节点发生短暂失联后重新连接,也会根据
master_repl_offset和second_repl_offset进行增量复制。 - 复制过程就是 Master 每执行一个写命令就会去 Slave 发送相同的写命令,Slave 接收并执行收到的写命令。
# 3.3 主从复制异步性
- 主从复制对于 Master 是非阻塞的,当 Slave 在进行主从复制同步过程中,Master 仍然可以处理外界的访问请求。
- 主从复制对于 Slave 是非阻塞的,当 Slave 在进行蛀虫复制过程中也可以接收外界的查询请求,只不过这时候 Slave 可能返回以前的老数据。
# 3.4 过期 key 处理
- Slave 不会让 key 过期,而是等待 Master 让 key 过期。当 Master 让 key 过期时,它会合成一个 del 命令并传输到所有的 Slave。
# 3.5 加速复制
- 默认情况下,Master 节点接收 SYNC 命令后执行 bgsave 操作,将数据先保存到磁盘,如果磁盘性能差,那么写入磁盘会消耗大量性能,因为在 Redis 2.8.18 后进行改进,可以设置无需写入磁盘直接发送 RDB 快照给 Slave,加速复制。
- 修改配置:
repli-diskless-sync yes(默认是 no)
# 4. 故障处理
# 4.1 主从数据一致性
- 主从网络延时
- 主多从少:部分重同步
- 主少从多:全量复制
# 4.2 数据延迟
- 编写外部程序监听主从节点的复制偏移量,延迟较大时发出报警或通知客户端,切换到主节点或其他节点。
- 设置 Slave 节点
slave-serve-stale-data为no,除INFO和SLAVEOF命令之外的任何请求都会返回一个错误SYNC with master in progress。
# 4.3 脏数据
原因:
- Redis 删除机制导致(惰性、定时、主动删除等)。
- 从节点可写导致。
解决:
- 忽略
- 选择性强制读主,从节点间接变成了备份服务器(只针对某个业务)。
- 从节点只读,规避从节点写入脏数据。
- 目前 Redis 读取数据之前会检查 key 过期时间来决定是否返回数据。
# 4.4 数据安全性
隐患:
关闭 Master 持久化会提升性能,同时会带来复制的安全性问题。
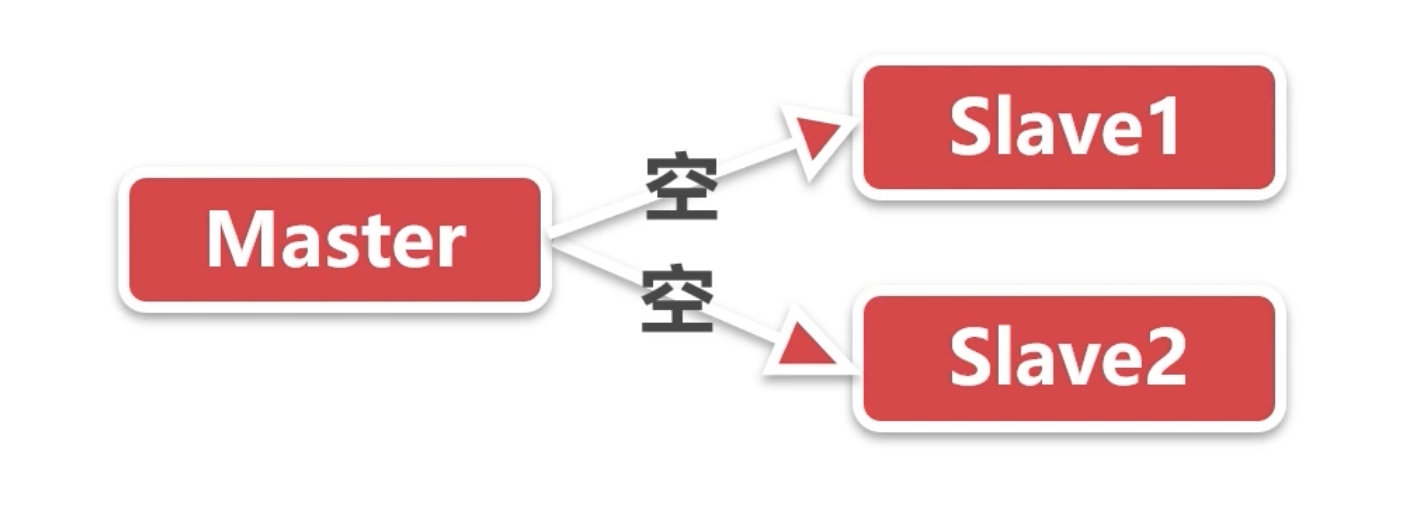
解决:
- 开启 Master 持久化。
- 在 Docker 或者脚本中设置 Master 不自动重启。
# 5. 性能优化
# 5.1 规避全量复制
- 第一次全量复制解决方案:低峰时段挂载 Slave。
- Slave 上已经有 Master 的数据了,可以选举 Slave 为主节点。
- 增大复制缓冲区大小(默认 1M),增加 offset 的命中率,降低全量复制改了。
# 5.2 规避复制风暴
复制风暴:多个节点同一时段下向 Master 复制请求,导致 Master 压力很大。
- 单主节点复制风暴:主节点重启,多从节点全量复制。
- 解决:
- 此时 Slave 有 Master 的数据了,可以选举 Slave 为主节点。
- 柱状复制结构。
- 解决:
- 单机多主复制风暴:一台机器上为了充分利用 CPU 资源,部署了多个主节点。
- 解决:
- 这事花钱能解决,把主节点分散在多台机器上就可以了。
- 解决: