
# 八、Redis 哨兵模式
# 1. 哨兵监控架构
# 1.1 Sentinel 基本架构
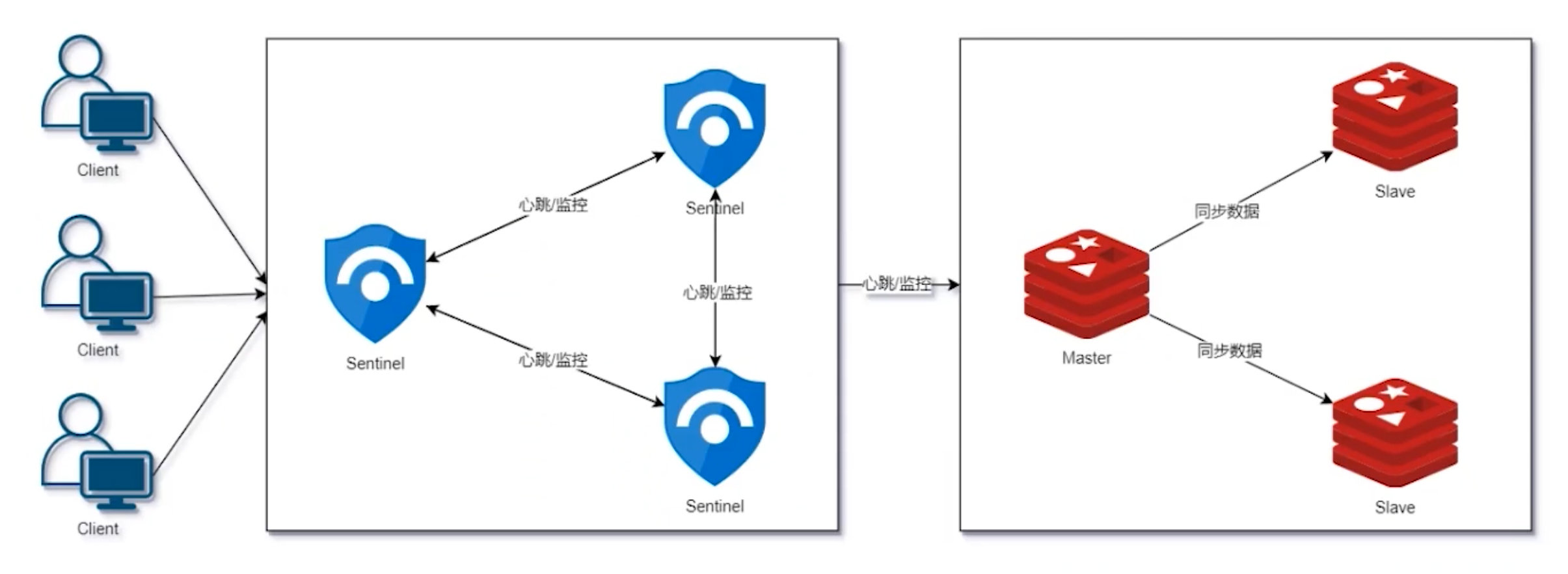
Redis Sentinel 是分布式系统中监控 Redis 主从服务器,并提供主服务器下线时自动故障转移功能的模式,其中四个特性为:
- 监控(monitoring)
- 提醒(notification)
- 自动故障迁移(Automatic failover)
- 配置提供者(Configuration provider)
# 1.2 Sentinel 分布式特性
Redis Sentinel 是一个分布式系统,可以在一个架构中运行多个 Sentinel 进程,优势如下:
- 降低了误报的可能性
- 降低对客户端的影响
- 任意 Sentinel 都可对外提供服务
# 1.3 Sentinel 部署前注意点
- 默认端口:26379
- 至少 3 个 Sentinel 实例
- 运行 Sentinel 必须制定配置文件
- 独立的虚拟机或物理机中运行
- 可配置 Sentinel 允许丢失有限的写入
- 客户端要支持 Sentinel
- 经常在测试环境中测试
- 在 Docker、端口映射或网络地址转换的环境中配置要格外小心
# 1.4 优点
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都有
- 有了哨兵之后主从可以自动切换,系统更健壮,可用性更高
- Sentinel 会不断地检查主从服务器是否运作正常,当贝监控的某个 Redis 服务器出现问题时,Sentinel 可以通过 API 向管理员或其他应用程序发送通知
# 1.5 缺点
- 主从切换需要时间,会丢失数据
- 还是没有解决主节点写的压力
- 主节点的写能力、存储能力受到单机的限制
- 动态扩容困难复杂,对于集群,容量达到上限时在线扩容会变得很复杂
# 2. 哨兵环境搭建
# 2.1 环境准备
- 搭建主从模式:Redis 主从模式
# 2.2 编写配置文件
三个节点分别创建 sentinel.conf:
vim /usr/local/redis/conf/sentinel.conf
添加一下内容:
# 放行所有 IP
bind 0.0.0.0
# 进程端口号
port 26379
# 后台启动
daemonize yes
# 日志记录文件
logfile "/usr/local/redis/log/sentinel.log"
# 进程编号记录文件
pidfile /var/run/sentinel.pid
# 指示 Sentinel 去监视一个名为 mymaster 的主服务器,最后的 2 表示仲裁,有 2 个节点连上了就判断没有断线(案例中共 3 节点)
sentinel monitor mymaster 172.16.58.200 6379 2
# 访问主节点的密码
sentinel auth-pass mymaster 123456
# Sentinel 认为服务器已经断线所需的毫秒数
sentinel down-after-milliseconds mymaster 10000
# 若 Sentinel 在该配置值内未能完成 failover 操作,则认为本次 failover 失败
sentinel failover-timeout mymaster 180000
# 2.3 启动服务
先关闭现有的 redis 服务
ps -ef | grep redis kill -9 PID再启动 3 个 redis 服务
/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf再启动 3 个 sentinel 服务
/usr/local/redis/bin/redis-sentinel /usr/local/redis/conf/sentinel.conf
# 3. 哨兵工作原理
# 3.1 日志分析
查看
sentinel.logcat /usr/local/redis/log/sentinel.log内容如下
# 加载 sentinel.conf 配置 46572:X 04 Aug 2021 19:22:38.380 # Configuration loaded 46572:X 04 Aug 2021 19:22:38.382 * Increased maximum number of open files to 10032 (it was originally set to 1024). # 运行一个 sentinel 节点 46572:X 04 Aug 2021 19:22:38.383 * Running mode=sentinel, port=26379. 46572:X 04 Aug 2021 19:22:38.383 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. 46572:X 04 Aug 2021 19:22:38.385 # Sentinel ID is 9b6c6d520bd4cbc939801a9206c5daf6bab76214 # 监控 mymaster 节点,仲裁为 2 46572:X 04 Aug 2021 19:22:38.385 # +monitor master mymaster 172.16.58.200 6379 quorum 2 46572:X 04 Aug 2021 19:22:38.386 * +slave slave 172.16.58.201:6379 172.16.58.201 6379 @ mymaster 172.16.58.200 6379 46572:X 04 Aug 2021 19:22:38.388 * +slave slave 172.16.58.202:6379 172.16.58.202 6379 @ mymaster 172.16.58.200 6379 # 发现其他的 sentinel 节点,也加进来 46572:X 04 Aug 2021 19:22:42.155 * +sentinel sentinel 439cd14c6448e3995062f56a5c9af611acedc52b 172.16.58.201 26379 @ mymaster 172.16.58.200 6379 46572:X 04 Aug 2021 19:22:43.288 * +sentinel sentinel da220efac4f9358479edd91715188fae38d28fdc 172.16.58.202 26379 @ mymaster 172.16.58.200 6379
# 3.2 定时任务
Sentinel 内部有 3 个定时任务,分别是:
- 每 1 秒每个 Sentinel 对其他 Sentinel 和 Redis 节点执行
ping操作(监控) - 每 2 秒每个 Sentinel 通过 Master 节点的 channel 交换信息(Publish/Subscribe)
- 每 10 秒每个 Sentinel 会对 Master 和 Slave 执行
INFO命令
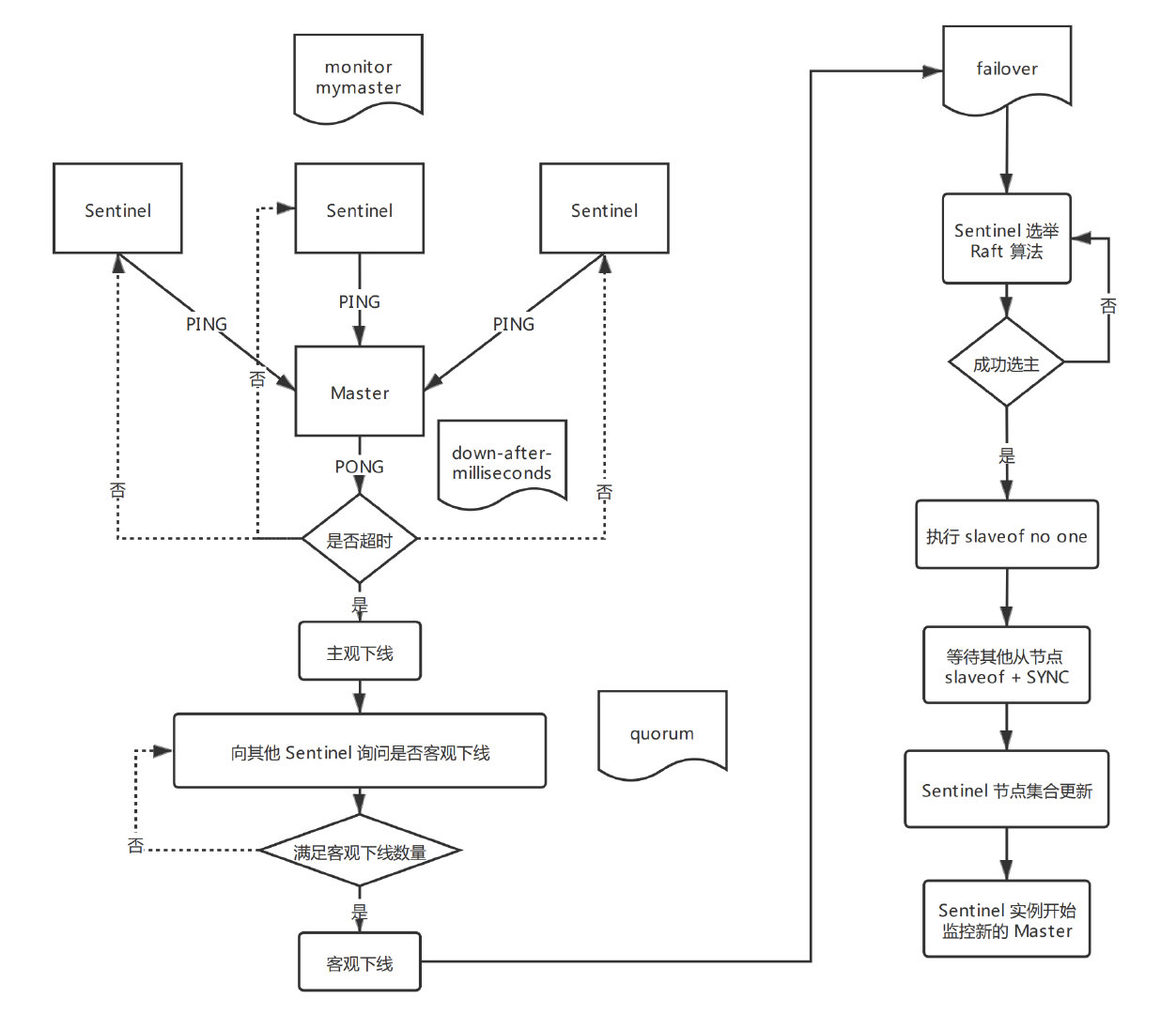
# 3.3 主观下线
所谓主观下线(Subjectively Down,简称 SDOWN)指的是单个 Sentinel 实例在对服务器做出的下线判断,即单个 Sentinel 认为某个服务下线(有可能是接收不到订阅,之间的网络不通等原因)。
# 3.4 客观下线
所谓客观下线(Objectively Down,检查 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断,并且通过命令互相交流之后,得出的服务器下线判断,然后开启 failover。
# 3.4 仲裁
仲裁指的是配置文件中的 quorum 选项。
# 最后面的 2
sentinel monitor mymaster 172.16.58.200 6379 2
quorum 的值一般设置为 Sentinel 个数的 n/2 + 1,例如 3 个 Sentinel 就设置为 2。
quorum 机制
抽屉原理:
- 一个群体 9 个人,有一个秘密,告诉给该群体中的任意 5 个人,那么随便挑选 5 个人,至少有 1 个人知道秘密。
quorum 机制:
quorum 机制是抽屉原理的一种实际应用,经常用于分布式系统,是一种少数服从多数的思想。
quorum 机制在分布式共识算法当中经常是用来减轻写的压力(相应的读压力会增大),如:
# 3.5 原理总结
- 每秒向其他 Sentinel 和 Master 以及 Slave 进行
ping; - 有效回复
ping命令的时间超过配置文件down-after-milliseconds选项所指定的值,就被认定为 主观下线; - 确认 主观下线 状态;
- 扩散 主观下线,寻求 客观下线;
- 大多数 Sentinel 判断 主观下线,条件满足,形成 客观下线;
- 投票选举 Master,然后 Slave 复制数据;
- 当 Master 被标记为 客观下线 后,
INFO命令触发由每 10s 一次改为每 1s 一次; - 若没有足够数量的 Sentinel 同意 Master 已经下线,Master 的客观下线状态就会被移除。若 Master 重新向 Sentinel 的
ping命令返回有效回复,Master 的主观下线状态就会被移除。
# 4. 故障转移演示
# 4.1 环境准备
- 先启动 3 个 redis
- 再启动 3 个 sentinel
# 4.2 开启 sentinel 日志监控
在
redis-slave1和redis-slave2分别运行:tail -f -n 10 /usr/local/redis/log/sentinel.log
# 4.3 停掉 Master
ps -ef | grep redis
kill -9 PID
# 4.4 分析日志
可以看到 redis-slave1 和 redis-slave2 的 sentinel.log 都有输出,我们随便拿 redis-slave1 来分析,下面将 redis-slave1 的 sentinel 称为 redis-sentinel-1:
# redis-sentinel-1 主观认为 172.16.58.200 下线
66980:X 04 Aug 2021 19:51:55.839 # +sdown master mymaster 172.16.58.200 6379
# 启动新的 Master 选举流程,后面数字代表选举的次数
66980:X 04 Aug 2021 19:51:55.849 # +new-epoch 1
# 投票选出一个 leader,该 leader 是负责进行 failover 的 sentinel
66980:X 04 Aug 2021 19:51:55.851 # +vote-for-leader 9b6c6d520bd4cbc939801a9206c5daf6bab76214 1
# 3 个 sentinel 中有 2 个认为 172.16.58.200 下线,满足条件,标记为客观下线
66980:X 04 Aug 2021 19:51:55.898 # +odown master mymaster 172.16.58.200 6379 #quorum 3/2
# 下一次故障转移最快开始时间
66980:X 04 Aug 2021 19:51:55.898 # Next failover delay: I will not start a failover before Wed Aug 4 19:57:56 2021
# 从 redis-sentinel-1 根据 redis-sentinel-0 那里更新配置
66980:X 04 Aug 2021 19:51:56.187 # +config-update-from sentinel 9b6c6d520bd4cbc939801a9206c5daf6bab76214 172.16.58.200 26379 @ mymaster 172.16.58.200 6379
# 更换 Master,从 172.16.58.200 换到 172.16.58.201
66980:X 04 Aug 2021 19:51:56.187 # +switch-master mymaster 172.16.58.200 6379 172.16.58.201 6379
# 新的 slave(原来的 redis-slave2)
66980:X 04 Aug 2021 19:51:56.187 * +slave slave 172.16.58.202:6379 172.16.58.202 6379 @ mymaster 172.16.58.201 6379
# 新的 slave(原来的 redis-master)
66980:X 04 Aug 2021 19:51:56.187 * +slave slave 172.16.58.200:6379 172.16.58.200 6379 @ mymaster 172.16.58.201 6379
# 因为原来的 redis-master 已经挂了,所以由判断它已经下线了
66980:X 04 Aug 2021 19:52:06.229 # +sdown slave 172.16.58.200:6379 172.16.58.200 6379 @ mymaster 172.16.58.201 6379
通过日志我们可以发现 172.15.58.201 成为了新的 Master 了,我们在原来的 redis-slave1 上查看 info replication:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=172.16.58.202,port=6379,state=online,offset=403866,lag=0
master_replid:cb5d5b6c3c83ff0ed54dcfd2a246f56fc9d3bdd2
master_replid2:84c5932a0eab5b1eae6bb1721dbfecb1dc91e925
master_repl_offset:403866
second_repl_offset:370485
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:403866
我们再来看原来的 redis-slave1 上的 sentinel.log,会发现已经多了一些内容了:
[root@k8s-node1 ~]# cat /usr/local/redis/conf/sentinel.conf
...
# Generated by CONFIG REWRITE
protected-mode no
user default on nopass ~* +@all
dir "/root"
sentinel auth-pass mymaster 123456
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
sentinel known-replica mymaster 172.16.58.200 6379
sentinel known-replica mymaster 172.16.58.202 6379
sentinel known-sentinel mymaster 172.16.58.202 26379 da220efac4f9358479edd91715188fae38d28fdc
sentinel known-sentinel mymaster 172.16.58.200 26379 9b6c6d520bd4cbc939801a9206c5daf6bab76214
sentinel current-epoch 1
# 5. 自动故障迁移流程
# 6. 节点管理
# 6.1 添加 Sentinel
添加单个 Sentinel:
- 只需要启动配置
sentinel monitor mastername监控当前活动主服务器的新 Sentinel 即可。
添加多个 Sentinel:
建议一个一个添加
添加结束后,可用命令
SENTINEL MASTER mastername检查所有 Sentinel 是否已经完全获取到所有的 Master 信息。[root@k8s-node1 ~]# /usr/local/redis/bin/redis-cli -p 26379 127.0.0.1:26379> SENTINEL MASTER mymaster
# 6.2 删除 Sentinel
注意
Sentinel 不会完全清除已经添加过的 Sentinel 信息。
需要移除一个 Sentinel,在没有网络隔离的环境下应遵循以下步骤:
- 停止要删除的 Sentinel 进程;
- 执行
SENTINEL RESET *向所有其他 Sentinel 实例发送命令; - 执行
SENTINEL MASTER mastername检查每个 Sentinel 显示的 Sentinel 数量是否一致。
# 6.3 删除旧的 Master 或无法访问的 Slave
注意
Sentinel 不会完全清除指定的 Master 和 Slave。
- 停止 Slave 进程;
- 向所有 Sentinel 发送命令
SENTINEL RESET mastername, 重置 mastername 所有状态信息。
# 7. 故障迁移一致性
Redis Sentinel 用到了分布式共识算法 Raft 来选举一个 Sentinel 节点为 leader。
- 确保了在一个给定的周期(epoch)内,最多只有一个 leader 产生;
- 这表示在同一个周期内,不会有 2 个 leader 同时产生,并且各个 Sentinel 在同一个节点中只会对一个 leader 进行投票;
- 配置更高的节点总是优于配置较低的节点,因为每个 Sentinel 都会主动使用更新的节点来代替自己的配置。
简单来说,我们可以将 Sentinel 的配置看作是一个带有版本号的状态。一个状态会以最后写入者胜出(last-write-wins)的方式(即最新的配置总是胜出),然后传播至其他所有的 Sentinel。
关于 Raft 算法
关于 Raft 算法的详细说明,可以参考笔者翻译的 Raft 论文:Raft 算法
# 8. TILT 模式
Sentinel 是通过心跳来获取其他 Slave,Master 和 Sentinel 的在线以及详细信息的,但是心跳除了因为网络分区,节点下线等问题丢失以外,自身机器的繁忙程度或者修改系统时间这些意外的操作也可能影响 Sentinel 的心跳正常工作,因此 Redis 为 Sentinel 提供了一个特殊的模式,称为 TILT,这个模式下,Sentinel 仍然会进行监控并收集信息,它只是不执行诸如故障转移、下线判断之类的操作而已。
void sentinelCheckTiltCondition(void) {
// 计算当前时间
mstime_t now = mstime();
// 计算上次运行 sentinel 和当前时间的差
mstime_t delta = now - sentinel.previous_time;
// 如果差为负数,或者大于 2 秒钟,那么进入 TILT 模式
if (delta < 0 || delta > SENTINEL_TILT_TRIGGER) {
// 打开标记
sentinel.tilt = 1;
// 记录进入 TILT 模式的开始时间
sentinel.tilt_start_time = mstime();
// 打印事件
sentinelEvent(REDIS_WARNING,"+tilt",NULL,"#tilt mode entered");
}
// 更新最后一次 sentinel 运行时间
sentinel.previous_time = mstime();
}
每次定时任务 Redis 都会执行上面这个函数,每次执行这个函数时都会产生一个 sentinel.previous_time,表示这次执行 Sentinel 逻辑的时间。如果上次执行 Sentinel 的时间早于当前时间(说明系统时间发生改变)或者两次执行 Sentinel 的时间相隔过长(代表当前系统繁忙,进程不能正常工作),Sentinel 就会进入 TILT 模式。
处于 TILT 模式,Sentinel 或持续监控所有状态,但:
- 停止处理请求。
- 当有实例向该 Sentinel 发送
SENTINEL is-master-down-by-addr命令时,Sentinel 返回负值:因为这个 Sentinel 所进行的下线判断已经不再准确。
如果 TILT 可以正常维持 30s(SENTINEL_TILT_PERIOD,默认 30s)时长,那么 Sentinel 退出 TILT 模式,TILT 模式是 Sentinel 的被动模式。