
# 七、缓存
# 1. 缓存机制
MySQL 缓存机制就是缓存 SQL 文本及缓存结果,用 KV 形式保存再服务器内存中,如果运行相同的 sql,服务器直接从缓存中去获取结果,不需要在再去解析、优化、执行 sql。 如果这个表修改了,那么使用这个表中的所有缓存将不再有效,查询缓存值得相关条目将被清空。表中得任何改变是值表中任何数据或者是结构的改变,包括 insert,update,delete,truncate,alter table,drop table 或者是 drop database 包括那些映射到改变了的表的使用 merge 表的查询,显然,这对于频繁更新的表,查询缓存不合适,对于一些不变的数据且有大量相同 sql 查询的表,查询缓存会节省很大的性能。
# 2. 命中条件
缓存存在一个 hash 表中,通过查询 SQL,查询数据库,客户端协议等作为 key,在判断命中前,MySQL 不会解析 SQL,而是使用 SQL 去查询缓存,SQL 上的任何字符的不同,如空格,注释,都会导致缓存不命中。
如果查询有不确定的数据,如 like now(),current_date(),那么查询完成后结果者不会被缓存,包含不确定的数的是不会放置到缓存中。
# 3. 工作流程
- 服务器接收 SQL,以 SQL 和一些其他条件为 key 查找缓存表;
- 如果找到了缓存,则直接返回缓存;
- 如果没有找到缓存,则执行 SQL 查询,包括原来的 SQL 解析,优化等;
- 执行完 SQL 查询结果以后,将 SQL 查询结果缓存入缓存表。
# 4. 缓存失败
当某个表正在写入数据,则这个表的缓存(命中缓存,缓存写入等)将会处于失效状态。
在 InnoDB 中,如果某个事务修改了这张表,则这个表的缓存在事务提交前都会处于失效状态,在这个事务提交前,这个表的相关查询都无法被缓存。
# 5. 缓存内存管理
缓存会在内存中开辟一块内存(query_cache_size)来维护缓存数据,其中大概有 40K 的空间是用来维护缓存数据的元数据的,例如空间内存,例如空间内存,数据表和查询结果映射,SQL 和查询结果映射的。
MySQL 将这个大内存块分为小内存块(query_cache_min_res_unit),每个小块中存储自身的类型、大小和查询结果数据,还有前后内存块的指针。
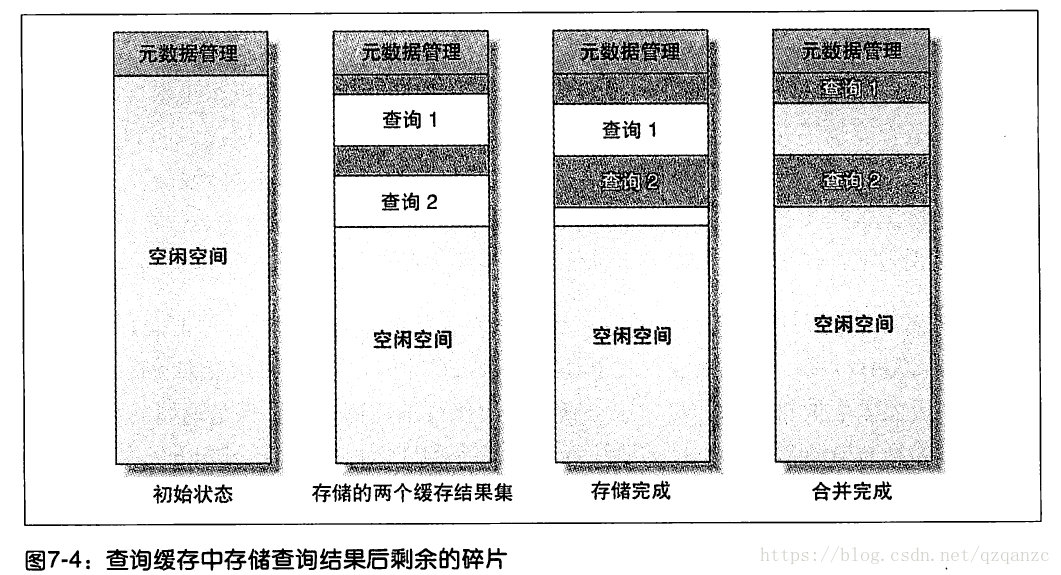
MySQL 需要设置单个小存储块大小,在 SQL 查询开始(还未得到结果)时就去申请一块内存空间,所以即使你的缓存数据没有达到这个大小也需要这个大小的数据块去保存(like linux filesystem’s block)。如果超出这个内存块的大小,则需要再申请一个内存块。当查询完成发现申请的内存有富余,则会将富余的内存空间是放掉,这就会造成内存碎片的问题,见下图:
# 6. InnoDB 与查询缓存
InnoDB 会对每个表设置一个事务计数器,里面存储当前最大的事务 ID。当一个事务提交时,InnoDB 会使用 MVCC 中系统事务 ID 最大的事务 ID 更新当前表的计数器。
只有比这个最大 ID 大的事务能使用查询缓存,其他比这个 ID 小的事务则不能使用查询缓存。
另外,在 InnoDB 中,所有有加锁操作的事务都不使用任何查询缓存。
查询必须是完全相同的(逐字节相同)才能够被认为是相同的。另外,同样的查询字符串由于其它原因可能认为是不同的。使用不同的数据库、不同的协议版本或者不同默认字符集的查询被认为是不同的查询并且分别进行缓存。
# 7. 缓存穿透
当查询缓存是无此 key 对应的值,后去数据库查询,数据库有值时存入缓存无值时返回无此值,但再一次查此 key 是还是一样的结果,但大量的访问此 key 是对数据库会造成更大的压力。
解决:
- 空值存储:当查询缓存是无此而已的值时,查询数据库,有值时存入缓存,物质是同样存入一个 null 并设置较短的有效时间,但再次查询此 key 时,查询结果的结果为 null 时展示无数据。
- 布隆过滤器
布隆过滤器
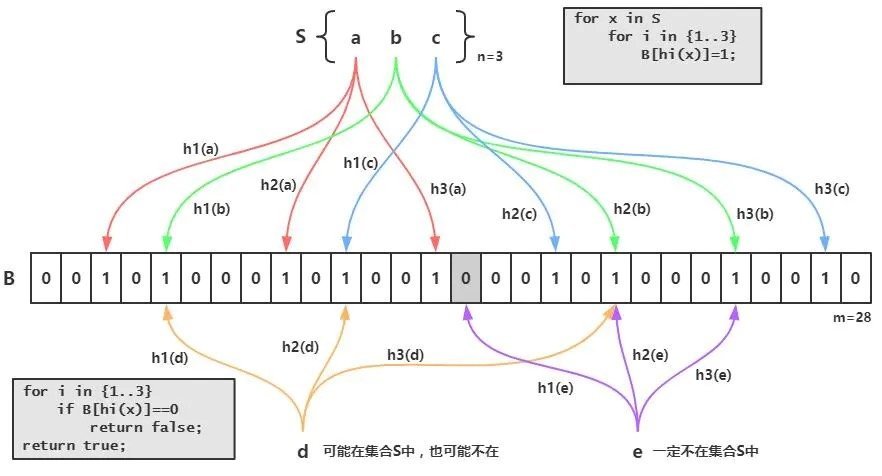
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于 检索一个元素是否在一个集合中 。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
基本概念:
- 如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为 O(n)、O(log n)、O(1)。
- 布隆过滤器的原理是:当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。这就是布隆过滤器的基本思想。
优点:
- 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入和查询时间都是常数 O(k)。另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
- 布隆过滤器可以表示全集,其它任何数据结构都不能。
- 使用同一组散列函数的两个布隆过滤器的交并运算可以使用位操作进行。
缺点:
- 但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
- 另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加 1,这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面。这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
解决缓存穿透:
- 当客户端进行查询时,先经过布隆过滤器,判断要查询的数据 key 是否在布隆数组当中,如果可能存在,则查询数据库,如果不可能存在,则返回空。
# 8. 缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决:
设置热点数据永远不过期。
加互斥锁,互斥锁参考代码如下:

说明:
1)缓存中有数据,直接走上述代码 13 行后就返回结果了
2)缓存中没有数据,第 1 个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待 100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据 key 值加锁就更好了,就是线程 A 从数据库取 key1 的数据并不妨碍线程 B 取 key2 的数据,上面代码明显做不到这点。
# 9. 缓存雪崩
在缓存服务器重启或大规模的缓存时间到期导致请求到访问数据库查询,使 MySQL 压力太大奔溃。
雪崩后的解决方案:
- 雪崩后关闭外网服务,对数据库 预热缓存 再开启外网服务。
避免雪崩策略
- 将缓存的 key 的到期时间设置为不同个的时间,避免同一个时间段大规模的缓存失效。
- 将缓存备份。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
# 10. 缓存预热
将常用的缓存提前存入缓存中。
← 六、MySQL 存储引擎 八、分库分表 →