
# 二、索引模块
- 为什么要使用索引?
- 什么样的信息能成为索引?
- 索引的数据结构?
- 密集索引和稀疏索引的区别?
# 1. 为什么要使用索引
索引是数据库中用来提高查询效率的技术,类似于目录。如果不使用索引,数据会零散的保存在磁盘块中,查询数据需要挨个遍历每一个磁盘块,直到找到数据为止,使用索引后会将磁盘块以树状结构保存,查询数据时会大大降低磁盘块的访问数量,从而提高查询效率。当然,如果表中的数据很少,使用索引反而会降低查询效率。
使用索引的核心目的非常简单,其实就是为了提高数据的查询速度。具体体现在以下几点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性;
- 添加索引后,可以大大加快数据的检索速度,这也是创建索引的最主要的原因;
- 索引可以加速表和表之间的连接,这样可以加快我们做联合查询时的速度;
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间;
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
# 2. 索引的副作用
索引是有大量数据的时候才建立的,没有大量数据反而会浪费时间,因为索引是使用二叉树建立。
当一个系统查询比较频繁,而新建,修改等操作比较少时,可以创建索引,这样查询的速度会比以前快很多。但同时这也会带来弊端,就是新建或修改等操作时,比没有索引或没有建立覆盖索引时的要慢。
索引并不是越多越好,太多索引会占用很多的索引表空间,甚至比存储一条记录更多。 对于需要频繁新增记录的表,最好不要创建索引,没有索引的表,执行 insert、append 都很快,有了索引以后,会多一个维护索引的操作,一些大表可能导致 insert 速度非常慢。
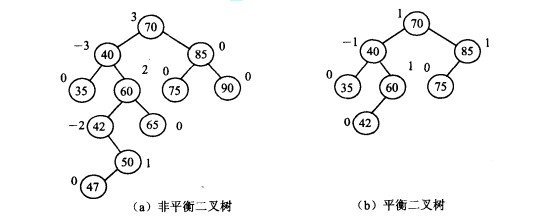
# 3. 平衡二叉树
# 图
# 性质
它是一棵空树或它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
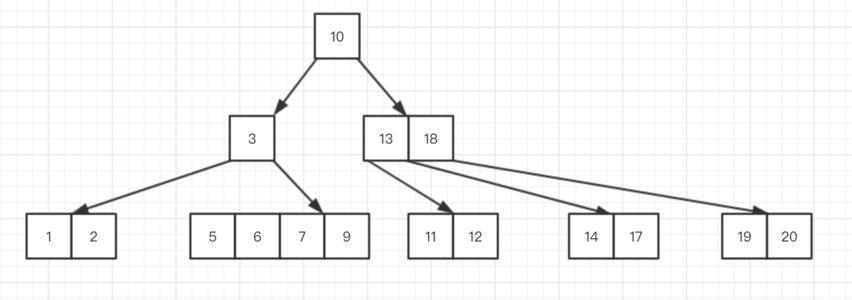
# 4. B 树
参考:https://zhuanlan.zhihu.com/p/27700617
# 图
# 性质
一棵 m 阶 B 树(balanced tree of order m)是一棵平衡的 m 路搜索树。它或者是空树,或者是满足下列性质的树:
1、每个结点至多有 m 个分支(子树),而最少分支要看是否为根结点:
- 是根非叶结点:至少 2 个分支
- 非根非叶结点:至少有 ⎡m/2⎤个分支
2、有 n(k≤n≤m)个分支的结点有 n-1 个关键字,它们按照递增顺序排序。k = 2(根结点)或 ⎡m/2⎤(非根结点)。
3、结点内各关键字互不相等。
4、叶子结点处于同一层,可以用空指针表示,是查找失败到达的位置。
# 查找
简单:相等停,大往右小往左。
# 插入
定义一个 5 阶树(平衡 5 路查找树;),现在我们要把 3、8、31、11、23、29、50、28 这些数字构建出一个 5 阶树出来;
遵循规则:
(1)节点拆分规则:当前是要组成一个 5 路查找树,那么此时 m = 5,关键字数必须 <= 5-1(这里关键字数 > 4 就要进行节点拆分);
(2)排序规则:满足节点本身比左边节点大,比右边节点小的排序规则;
先插入 3、8、31、11

再插入 23、29

再插入 50、28

# 删除
(1)节点合并规则:当前是要组成一个 5 路查找树,那么此时 m=5,关键字数必须大于等于 ceil(5/2)(这里关键字数 < 2 就要进行节点合并);
(2)满足节点本身比左边节点大,比右边节点小的排序规则;
(3)关键字数小于二时先从子节点取,子节点没有符合条件时就向向父节点取,取中间值往父节点放;
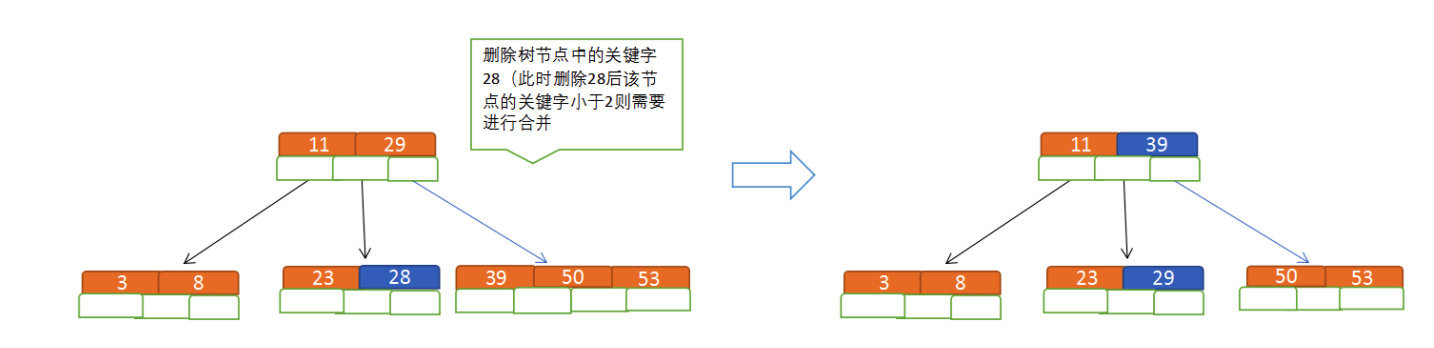
# 特点
B 树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在 B 树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为 4K,每次 IO 进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度。
# 5. B+ 树
参考:http://data.biancheng.net/view/61.html
# 图
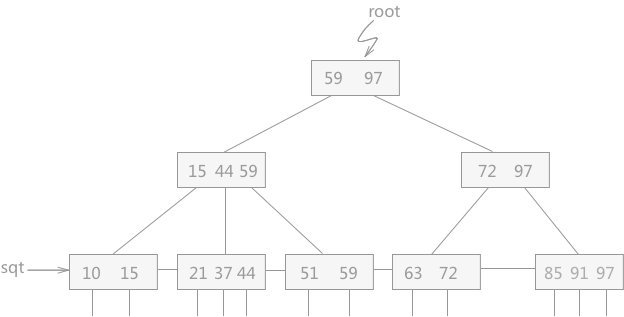
# 性质
B+ 树是 B 树的一种变形形式,B+ 树上的叶子结点存储关键字以及相应记录的地址,叶子结点以上各层作为索引使用。
1、在 B+ 树中,具有 n 个关键字的结点含有 n 个分支;而 B 树中,具有 n 个关键字的结点含有 n-1 个分支。
2、B+ 树结点的关键数个数 n 取值:
- 根结点:2≤n≤m(B 树中是 1≤n≤m-1)
- 其他: ⎡m/2⎤≤n≤m(B 树中是⎡m/2⎤-1≤n≤m-1)
# 查找
对 B+ 树可以进行两种查找运算:
- 从最小关键字开始,进行顺序查找。
- 从根结点开始,进行树的方式查找
# 插入
1、 若被插入关键字所在的结点,其含有关键字数目小于阶数 M(例图中的 M=3),则直接插入结束;
例如,在图 1 中插入关键字 13:
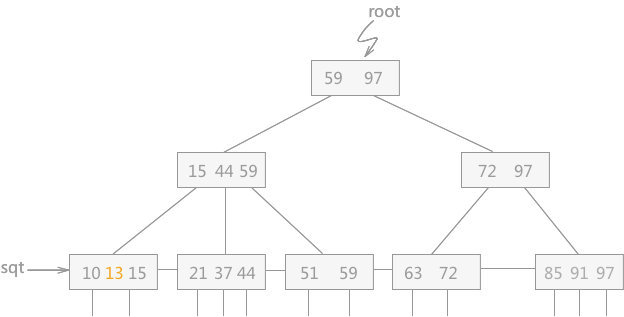
2、 若被插入关键字所在的结点,其含有关键字数目等于阶数 M,则需要将该结点分裂为两个结点,一个结点包含⌊M/2⌋,另一个结点包含⌈M/2⌉。同时,将⌈M/2⌉的关键字上移至其双亲结点。假设其双亲结点中包含的关键字个数小于 M,则插入操作完成。
例如,在图 1 的基础上插入关键字 95:

3、在第 2 情况中,如果上移操作导致其双亲结点中关键字个数大于 M,则应继续分裂其双亲结点。
例如,在图 1 的 B+ 树中插入关键字 40,则插入后的 B+ 树如图 4 所示:
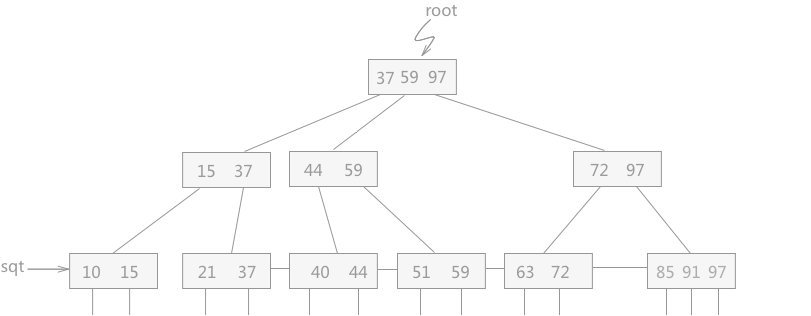
# 删除
1、 找到存储有该关键字所在的结点时,由于该结点中关键字个数大于⌈M/2⌉,做删除操作不会破坏 B+ 树,则可以直接删除。
例如,在图 1 所示的 B+ 树中删除关键字 91,删除后的 B+ 树如图 5 所示:

2、 当删除某结点中最大或者最小的关键字,就会涉及到更改其双亲结点一直到根结点中所有索引值的更改。
例如,在图 1的 B+ 树中删除关键字 97,删除后的 B+ 树如图 6 所示:

3、 当删除该关键字,导致当前结点中关键字个数小于⌈M/2⌉,若其兄弟结点中含有多余的关键字,可以从兄弟结点中借关键字完成删除操作。
例如,在图 1 的 B+ 树中删除关键字 51,由于其兄弟结点中含有 3 个关键字,所以可以选择借一个关键字,同时修改双亲结点中的索引值,删除之后的 B+ 树如图 7 所示:
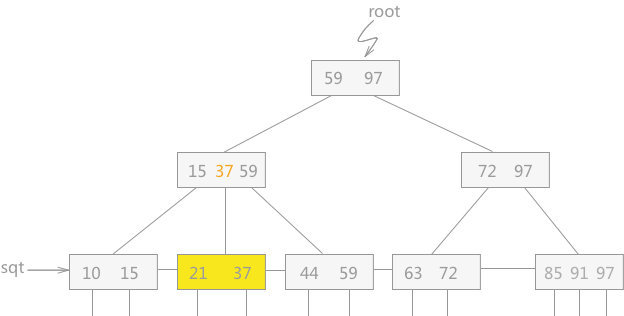
4、 第 3 种情况中,如果其兄弟结点没有多余的关键字,则需要同其兄弟结点进行合并。
例如,在图 7 的 B+ 树种删除关键字 59,删除后的 B+树为:

5、 当进行合并时,可能会产生因合并使其双亲结点破坏 B+ 树的结构,需要依照以上规律处理其双亲结点。
例如,在图 6 的 B+ 树中删除关键字 63,当删除后该结点中只剩关键字 72,且其兄弟结点中只有 2 个关键字,无法实现借的操作,只能进行合并。但是合并后,合并后的效果图如图 9 所示:
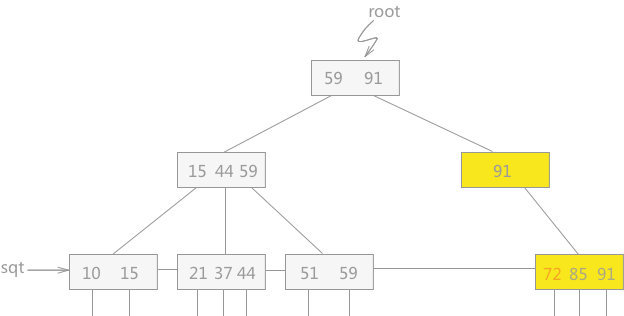
如图 9 所示,其双亲结点中只有一个关键字,而其兄弟结点中有 3 个关键字,所以可以通过借的操作,来满足 B+树的性质,最终的 B+ 树如图 10 所示:
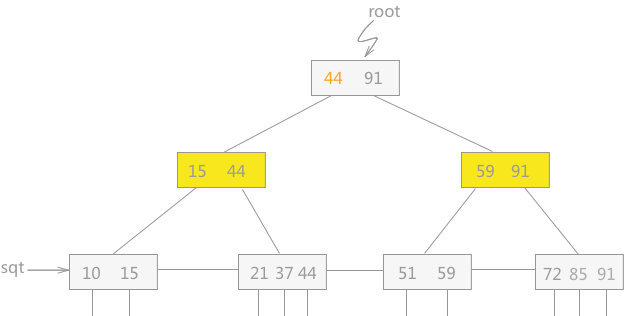
# 特点
- B+ 树的 层级更少:相较于 B 树 B+ 每个 非叶子 节点存储的关键字数更多,树的层级更少所以查询数据更快;
- B+树 查询速度更稳定:B+ 所有关键字数据地址都存在 叶子 节点上,所以每次查找的次数都相同所以查询速度要比 B 树更稳定;
- B+ 树 天然具备排序功能: B+ 树所有的 叶子 节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高;
- B+ 树 全节点遍历更快: B+ 树遍历整棵树只需要遍历所有的 叶子 节点即可,而不需要像 B 树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B 树 相对于 B+ 树 的优点是,如果经常访问的数据离根节点很近,而 B 树 的 非叶子 节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比 B+ 树 快。
# 6. Hash 索引

- 仅仅能满足
=,IN,不能使用范围查询; - 无法被用来避免数据的排序操作;
- 不能利用部分索引键查询;
- 不能避免表扫描;
- 遇到大量 Hash 值相等的情况后性能并不一定就会比 B Tree 索引高。
# 7. Bitmap 索引
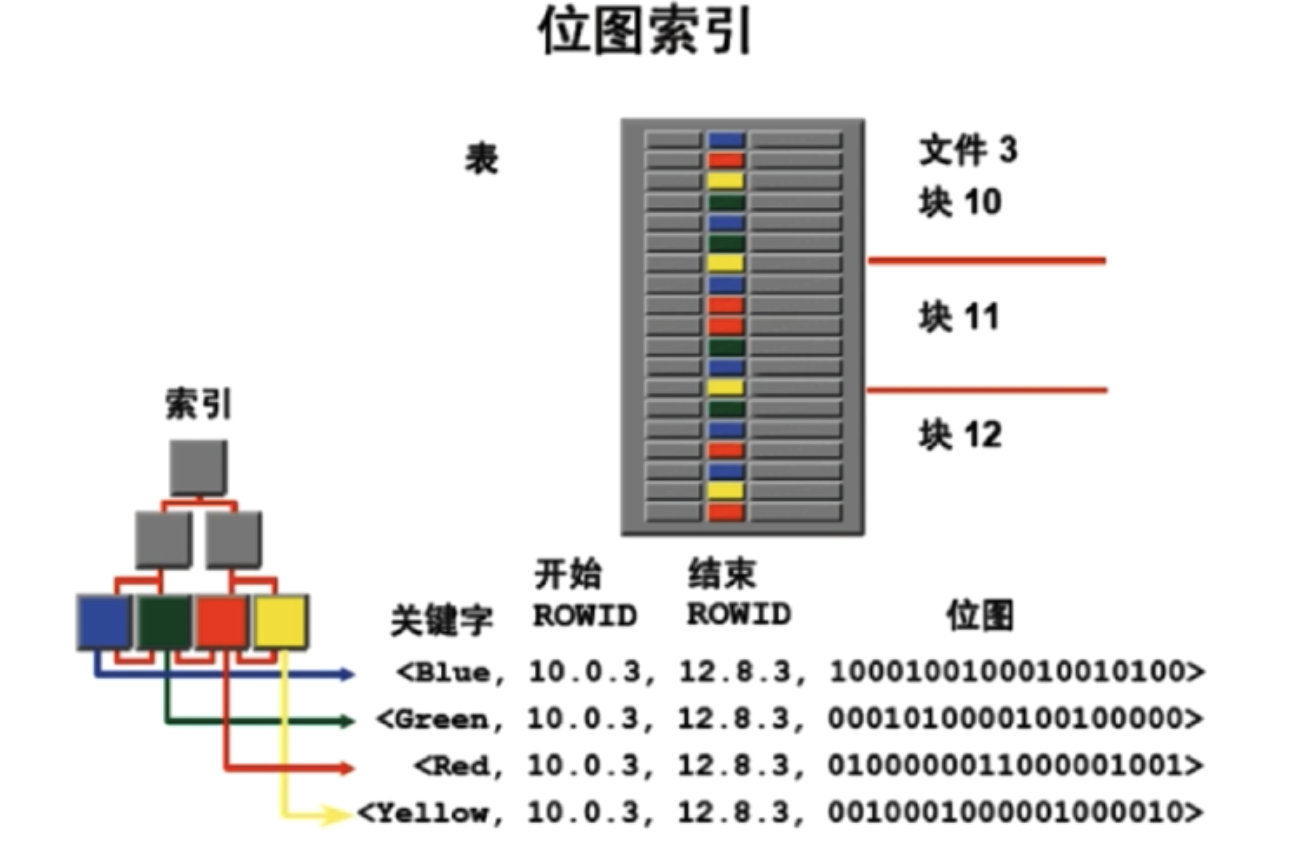
- 很多数据库不支持,Oracle 支持;
- 当值只有固定的几种情况的时候才可以使用(如性别只有男、女这两种情况);
- 不适合高并发情景,因为加锁很严格。
# 8. 稠密索引和稀疏索引
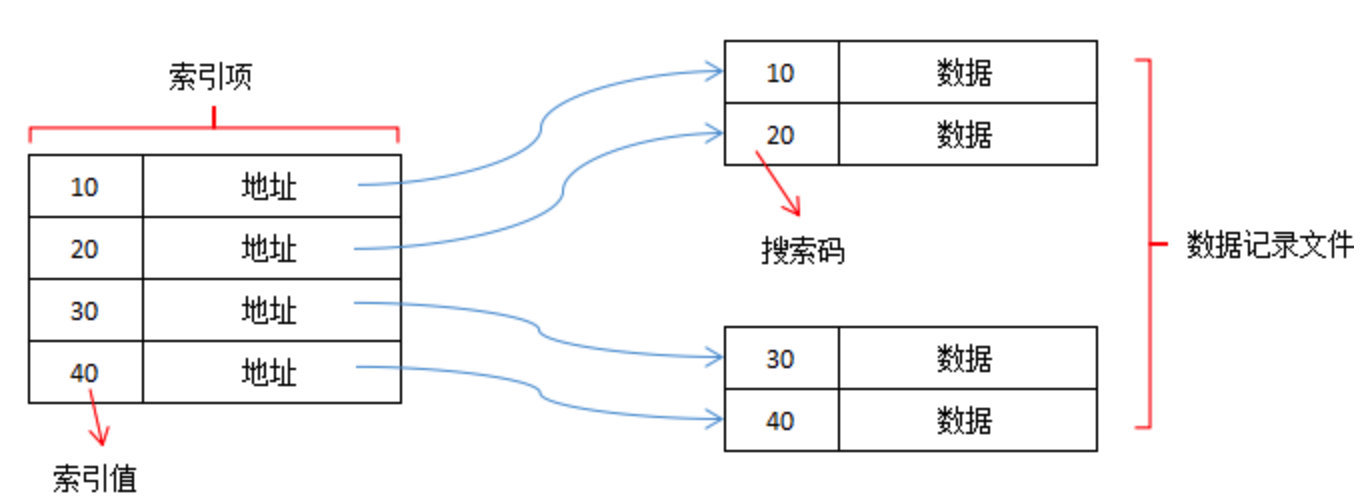
# 稠密索引
在稠密索引中,文件中的每个搜索码值都对应一个索引值。
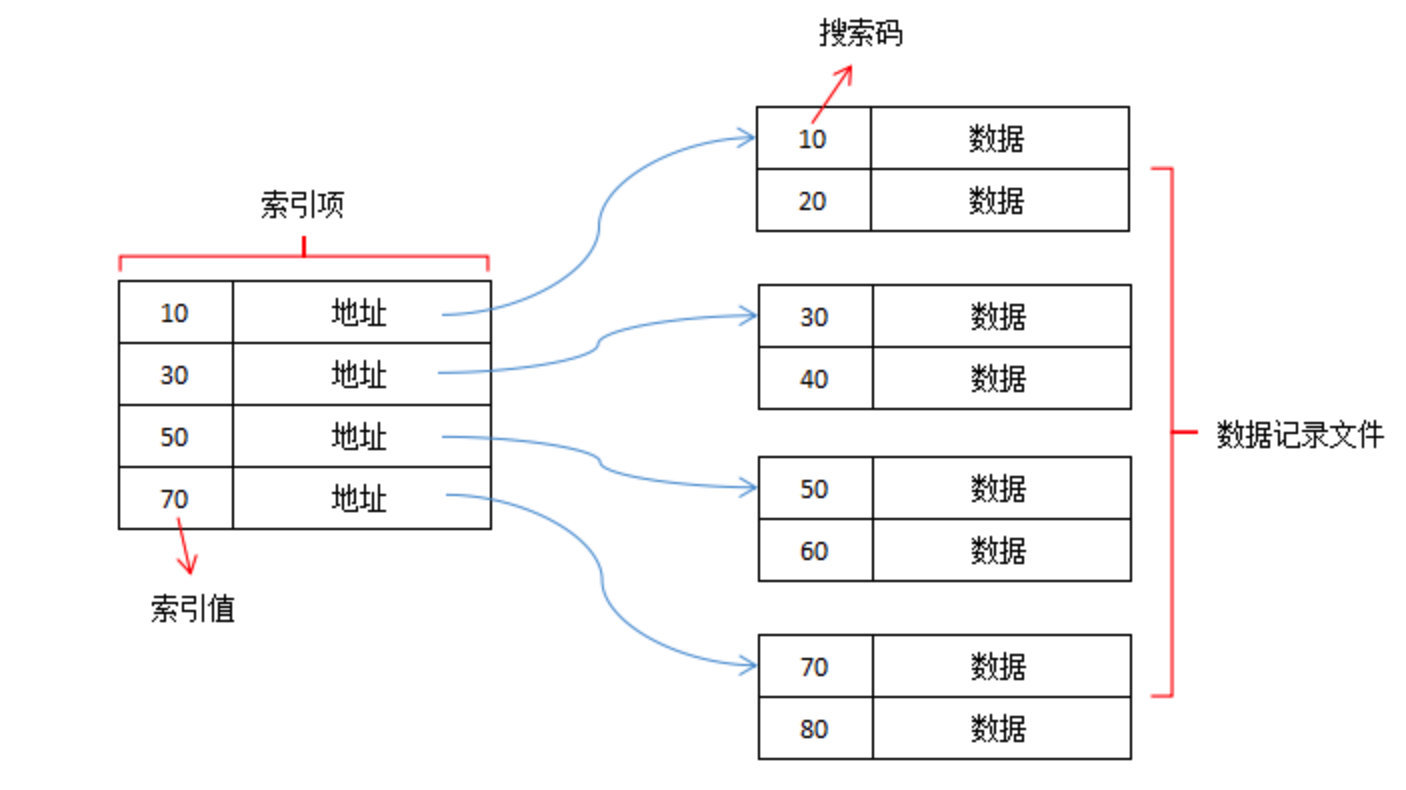
# 稀疏索引
在稀疏索引中,只为搜索码的某些值建立索引项。也就是说,稀疏索引为数据记录文件的每个存储块设一个键-指针对,存储块意味着块内存储单元连续。
# 区别
- 稠密索引文件中的每一个搜索码值都对应一个索引值;稀疏索引文件只为索引码的某些值建立索引项;
- 稠密索引查找时间较短,索引存储空间较大;稀疏索引占用的索引存储空间比较小,但是查找时间较长。
# 8. SQL 调优
- 根据慢日志定位慢查询 SQL
- 使用 explain 等工具分析 SQL
- 修改 SQL 或者尽量让 SQL 走索引
# 9. 联合索引的最左匹配原则的成因
# 演示
创建一个表,其中有一个联合索引为
..., KEY 'index_area_title' ('area', 'title'), ...;按照 area 和 title 来查 ——> 走了
index_area_title索引
只按照 area 来查 ——> 依旧走了
index_area_title索引
只按照 title 来查 ——> 不走索引
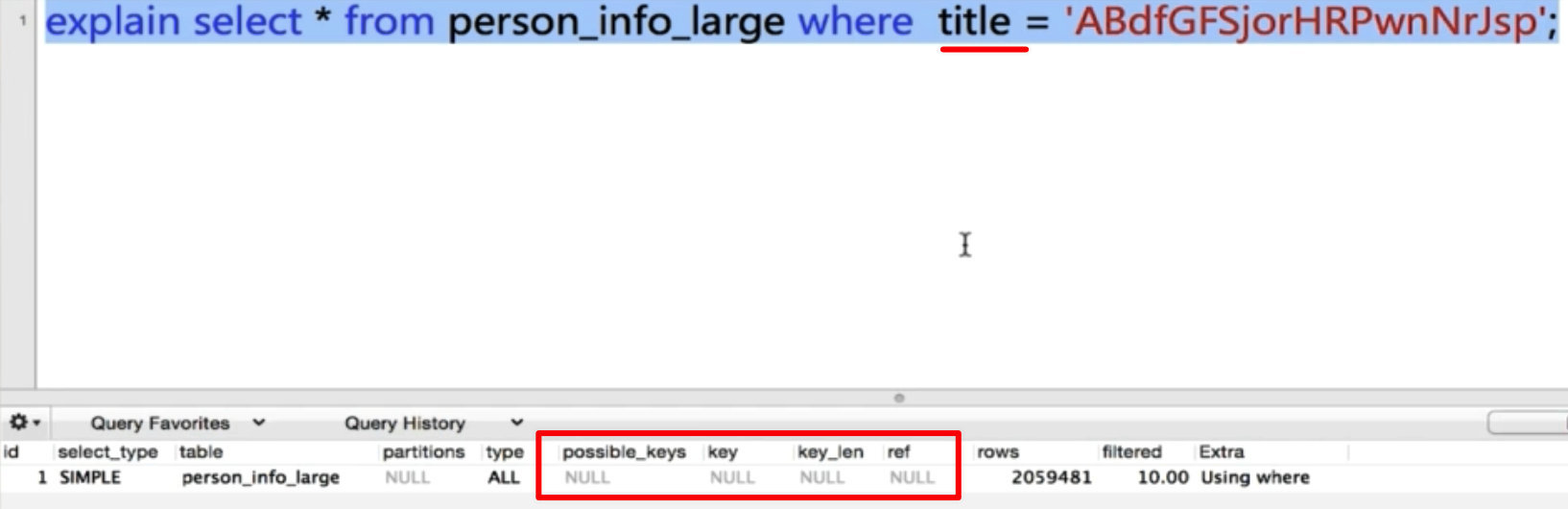
# 解释
假设组合索引为:a,b,c 的话;那么当 SQL 中对应有:a 或 a,b 或 a,b,c 的时候,可称为完全满足最左原则;当 SQL 中查询条件对应只有 a,c 的时候,可称为部分满足最左原则;当 SQL 中没有 a 的时候,可称为不满足最左原则。
补充
MySQL5.7 开始会自动优化,如:会把 c,b,a 优化为 a,b,c 使之完全遵循最左原则;会把 c,a 优化为 a,c 使之部分遵循最左原则。即 SQL 语句中的对应条件的先后顺序无关。
# 成因
MySQL 创建联合索引是首先会对最左边,也就是第一个索引字段进行排序
在第一个排序的基础上,再对第二个索引字段进行排序,其实就像是实现了 Order by字段 1,再 Order by 字段 2 这样一种排序规则。所以第一个字段是绝对有序的,而第二个字段就是无序的了
因此通常情况下,直接使用第二个字段进行条件判断是用不到索引的。这就是为什么 MySQL 要强调最左匹配原则的成因。
# 10. 如何创建索引
# PRIMARY KEY(主键索引)
ALTER TABLE 'table_name' ADD PRIMARY KEY ('column');
# UNIQUE KEY(唯一索引)
ALTER TABLE 'table_name' ADD UNIQUE ('column');
# INDEX(普通索引)
ALTER TABLE 'table_name' ADD INDEX index_name ('column');
# FULLTEXT(全文索引)
ALTER TABLE 'table_name' ADD FULLTEXT ('column');
# 多列索引
ALTER TABLE 'table_name' ADD INDEX index_name ('column1','column2','column3');
# 11. 如何删除索引
ALTER TABLE 'table_name' DROP INDEX index_name;